"En esta extensa entrada se repasa uno de los métodos más comunes para proporcionar conectividad IP desde las máquinas virtuales, contenidas en el Host KVM, hacia las redes externas, la utilización de bridges e interfaces TAP, tanto en su variante L2 (bridged mode) como en L3 (routed mode)"

Como otros hipervisores, KVM permite elegir entre varias opciones a la hora de proporcionar acceso a la red física desde las máquinas virtuales que albergan. En esta entrada, se revisarán los métodos que utilizan bridges y taps para ello. No es el único modo, ya que se podría elegir por ejemplo:
Es importante resaltar que esta entrada no es una guía de configuración de red de los KVMs, y que se ciñe solo al repaso del método de bridges y taps para dar conectividad a las máquinas virtuales. No se entra en la configuración de las interfaces de gestión, PXE, etc del propio Host KVM. Tampoco se tocarán temas adicionales, como los movimientos de máquinas virtuales entre KVMs, Openstack, integraciones,...
Pensando en el método de bridges y TAPs, KVM puede proveer a las VMs de dos medios de acceso al exterior: "Routed mode" y "Bridge mode". En el bridge mode, también nombrado como "Shared Physical Device", las máquinas virtuales aparecerán como si estuviesen directamente conectadas a las redes existentes, mientras que en el modo routed se crearía una "red virtual" (que contendría sus servicios propios, como por ejemplo el servicio DHCP), y que sería enrutada por el propio Host KVM hacia las redes externas, es decir, el Host KVM estaría actuando de router, enmascarando las máquinas virtuales (las MACs no se verían, e incluso se podría ocultar por NAT sus direcciones IP).
La entrada se divide en dos partes: "L2 - bridge mode", y "L3 - routed mode", dentro de las cuales se explica cada uno de esos métodos.
Esa explicación, a su vez estará dividida en dos partes, el repaso teórico y unos ejemplos prácticos. Los ejemplos siempre serán 3: una configuración manual, la configuración utilizando herramientas CLI y la configuración utilizando herramientas GUI (la herramienta en ambos casos será libvirt, una API de configuración), pero en todo caso se intenta que el resultado sea muy similar, para que se pueda apreciar mejor cuál es el trabajo que hace por debajo la herramienta libvirt.
L2 - bridge mode
El método bridge permite emular una conectividad L2 entre las máquinas virtuales y los elementos externos al Hardware del Host donde se encuentran localizadas, para lo cual se emula un switch interno en el cual se conectan las máquinas virtuales, cuyo tráfico alcanzará al exterior por las interfaces NICs físicas que también estarán asociadas a ese "switch emulado".
Se han de crear elementos bridge dentro de la configuración de KVM, los cuales permiten compartir las conexiones entre las interfaces que forman parte de ellos, donde se vincularán tanto las interfaces físicas del host KVM (para proporcionar la conectividad externa) como las interfaces virtuales de las máquinas virtuales.

Como se puede ver, los métodos active-backup, broadcast y TLB no permiten el balanceo de carga. Por su parte ALB modifica las MACs origen, y tanto Round Robin como XOR no tienen una interacción con el switch que garantice la consistencia del agregado, es por ello que el método recomendado es LACP.
No obstante, hay que tener también presente que para configurar en los switches que conectan a los KVMs, los agregados estáticos (modos Round-Robin y XOR) o los agregados dinámicos (LACP), ambas interfaces deben pertenecer a un mismo switch físico, o a un stack de switches (ver entrada TRILL, SPB, VXLAN, NVGRE, EVI, OTV, EVB, VNTag: nuevas soluciones para antiguos problemas donde se comenta más en detalle esta necesidad a la hora de crear los agregados en los switches), por lo que en ciertas ocasiones puede ser aconsejable utilizar otros modos de bonding.
Para finalizar con respecto a los bondings, es importante tener en cuenta el método de monitorización del enlace, que puede hacerse de dos modos (son mutuamente excluyentes):
También hay que pensar que con LACP se prueba en cierta medida la conectividad, al existir la necesidad de interacción entre el Host y el switch para formar el bonding.
Si se añade un bonding, el anterior esquema se vería del siguiente modo:









Si no se quisiesen utilizar VLANs, o se desease un bridge a la VLAN nativa, el fichero tendría que crear el bridge a la vez que el bonding. Este sería el aspecto:
vi /root/make_br555.xml
Y se inician:
Se comprueba que ya se encuentran activas:
También se puede comprobar con el comando brctl que los bridges han sido creados:
Del mismo modo que se hizo anteriormente, se puede crear la máquina virtual:




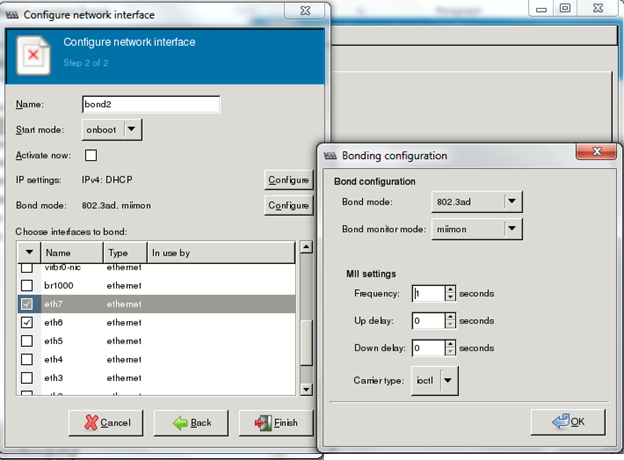









Figura 24 - Ejemplo de esquema de conexión routed mode


Figura 26 - Representación simplificada del ejemplo routed mode con 802.1q en enlace externo
Para el primer caso, esa interfaz dummy no será otra cosa que una interfaz TAP. Para crear esta interafaz TAP, se puede crear un script destinado a ello, tal y como se explica en esta web, se puede utilizar un Software llamado tunctl, así como creando un nuevo fichero de interfaz, de modo que no exista problema de persistencia tras reinicios.
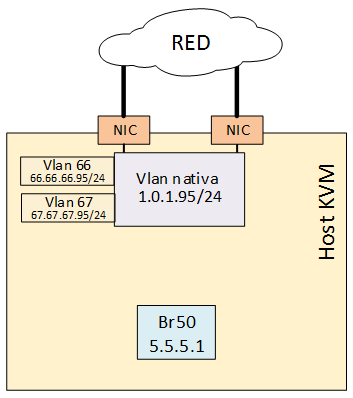
Figura 27 - Representación de la conectividad L2 del ejemplo de configuración manual
En la salida se pueden apreciar tres partes diferenciadas:
La regla a añadir podría ser muy genérica, permitiendo el reenvío de todos los paquetes, sin depender de su origen o destino. Esta configuración sería más sencilla pero menos segura y flexible, por lo que se añadirán reglas específicas para las redes virtuales (las redes 5.5.5.0/24 y 6.6.6.0/24 que son con las que se generaron los bridges de ejemplo).
Para cada bridge se deberán crear una serie de reglas, por ejemplo, para permitir el forwarding de paquetes entre el bridge br50 y el exterior (y con el otro bridge), se deberán incluir:
iptables -A FORWARD -i br50 -o bond50 -s 5.5.5.0/24 -j ACCEPT
iptables -A FORWARD -i br50 -o br50 -j ACCEPT
iptables -A FORWARD -o br50 -j REJECT
iptables -A FORWARD -i br50 -j REJECT

Esta sería la representación gráfica de la configuración llegado este punto:

En este momento ya se podrá crear una máquina virtual y vincularla al bridge br50:
virt-install --name=VM_L3_test --arch=x86_64 --vcpus=1 --ram=512 --os-type=linux --hvm --connect=qemu:///system --network bridge:br50 --vnc --noautoconsole --nodisk --boot cdrom
Con este último paso se completaría el esquema buscado:

Y el resto se podrán hacer mediante libvirt:

virt-install --name=VM_L3_testlibvirt --arch=x86_64 --vcpus=1 --ram=512 --os-type=linux --hvm --connect=qemu:///system --network bridge:virtualbr0 --vnc --noautoconsole --nodisk --boot cdrom



Se le asignará un nombre:

Un rango de direccionamiento:

También se especificará si se desea activar el DHCP y los parámetros de este:

Una vez completado el paso del DHCP, se deberá seleccionar el tipo de red virtual. Se puede elegir aislado ("isolated") o forwarding, para lo cual hay que elegir la interfaz externa a la que se enrutará el tráfico (bond800 en este ejemplo):

Ya que se ha elegido el tipo forwarding, se debe hacer también la selección de si su comportamiento implicará NAT o solo será routing:

Una vez finalizado, y tras pulsar "Finish", en la pantalla general se podrán revisar los parámetros de la nueva red virtual. También se podrá consultar el nombre del nuevo bridge interno que se ha creado para conectar las máquinas virtuales, virbr0 en este caso:
Con esto, ya se dispondrá de la red virtual, por lo que se podrá vincular a las máquinas virtuales. Si se crea una máquina virtual de pruebas nueva (siguiendo los mismos pasos que los mostrados en el ejemplo del bridge mode), cuando se procede a la selección de la conexión de la vNIC, ya aparecerán las redes virtuales, tanto la creada por CLI, como por GUI. Para utilizar la red creada manualmente, habría que seleccionar el bridge que se creo a tal efecto (br50):

Para poder comprobar el funcionamiento del DHCP, o el resto de elementos, habrá que utilizar el CLI tal y como se ha visto en los ejemplos anteriores.
- Realización de bridges + TAPs, el cual será comentado en esta entrada.
- Utilización de OpenvSwitch (o Software similar), que permite la introducción de un módulo configurable para manejar el comportamiento L2 de los KVMs y sus máquinas virtuales (ver "KVM y Open vSwitch (OVS): Componentes, ventajas y configuración de conectividad básica para máquinas virtuales").
- Configuración del driver MACVTAP. Este driver, el cual también se repasará en una futura entrada, permite la configuración de arquitecturas EVB (VEPA) (ver "KVM: Driver Macvtap para la conexión de VMs").
Es importante resaltar que esta entrada no es una guía de configuración de red de los KVMs, y que se ciñe solo al repaso del método de bridges y taps para dar conectividad a las máquinas virtuales. No se entra en la configuración de las interfaces de gestión, PXE, etc del propio Host KVM. Tampoco se tocarán temas adicionales, como los movimientos de máquinas virtuales entre KVMs, Openstack, integraciones,...
Pensando en el método de bridges y TAPs, KVM puede proveer a las VMs de dos medios de acceso al exterior: "Routed mode" y "Bridge mode". En el bridge mode, también nombrado como "Shared Physical Device", las máquinas virtuales aparecerán como si estuviesen directamente conectadas a las redes existentes, mientras que en el modo routed se crearía una "red virtual" (que contendría sus servicios propios, como por ejemplo el servicio DHCP), y que sería enrutada por el propio Host KVM hacia las redes externas, es decir, el Host KVM estaría actuando de router, enmascarando las máquinas virtuales (las MACs no se verían, e incluso se podría ocultar por NAT sus direcciones IP).
La entrada se divide en dos partes: "L2 - bridge mode", y "L3 - routed mode", dentro de las cuales se explica cada uno de esos métodos.
Esa explicación, a su vez estará dividida en dos partes, el repaso teórico y unos ejemplos prácticos. Los ejemplos siempre serán 3: una configuración manual, la configuración utilizando herramientas CLI y la configuración utilizando herramientas GUI (la herramienta en ambos casos será libvirt, una API de configuración), pero en todo caso se intenta que el resultado sea muy similar, para que se pueda apreciar mejor cuál es el trabajo que hace por debajo la herramienta libvirt.
L2 - bridge mode
El método bridge permite emular una conectividad L2 entre las máquinas virtuales y los elementos externos al Hardware del Host donde se encuentran localizadas, para lo cual se emula un switch interno en el cual se conectan las máquinas virtuales, cuyo tráfico alcanzará al exterior por las interfaces NICs físicas que también estarán asociadas a ese "switch emulado".
Se han de crear elementos bridge dentro de la configuración de KVM, los cuales permiten compartir las conexiones entre las interfaces que forman parte de ellos, donde se vincularán tanto las interfaces físicas del host KVM (para proporcionar la conectividad externa) como las interfaces virtuales de las máquinas virtuales.
Para "conectar" las máquinas virtuales a los bridges hay que hacer uso de interfaces TAPs, para obtener las vNICs de cada VM. Los TAPs no son más que interfaces Software, es decir, interfaces que no tienen vinculado ningún Hardware específico. Los TAPs no solo son utilizados para emular las vNICs, sino también para realizar otro tipo de configuraciones como pueden ser VPNs, monitorizaciones, etc.
A continuación se puede ver en simple esquema de conexión:
Figura 1 - Conexión de VMs mediante bridge
Cuando una de las dos VMs quiera comunicarse a nivel 2 con otra dentro del mismo host KVM, enviará los paquetes por su vNIC (TAP) utilizando la MAC virtual del interfaz TAP como MAC origen. Al llegar al bridge, este busca en su tabla de MACs asociadas y lo enviará por el TAP o interfaz externo (ethx) correcto.
Si no se desea que las máquinas tengan conectividad hacia el exterior (redes virtuales aisladas) simplemente se configuraría un bridge sin ninguna NIC física vinculada.
Si se configura una dirección IP en el propio interfaz del bridge, esta IP utilizará la dirección MAC del bridge, la cual, por defecto, es autogenerada escogiendo la dirección MAC más "baja" de entre todas las MAC que tienen las interfaces conectadas a él.
Esto puede ser un problema cuando se utilizan los mismos bridges para dar conectividad a las VMs, las cuales tendrán MACs propias (las de los TAPs), ya que estas se generan y destruirán dinámicamente, de tal modo que si se crea una nueva máquina virtual, y da la casualidad de que la MAC del TAP (la cual se generará aleatoriamente) es menor que todas las MACs del resto de TAPs e interfaces físicas asociadas al bridge, el mismo bridge podría tomar como suya esta nueva dirección MAC, sustituyendo a la antigua. Esto provocaría una pérdida de conectividad y un reinicio de todas las conexiones existentes, ya que todos los nuevos paquetes serán enviados y esperados en la nueva MAC.
Para solventar eso es recomendable fijar la dirección MAC del bridge, utilizando, por ejemplo, la MAC de la interfaz que transmitirá los paquetes al exterior (eth0, por ejemplo), ya que estas no se generan y destruyen dinámicamente.
Redundancia de enlaces externos
Para poder añadir redundancia de los enlaces externos, para estar protegidos ante un eventual fallo de la NIC física, se han de configurar bondings. Los bondings son agregaciones de interfaces físicos, los cuales pueden ser utilizados tanto para garantizar la alta disponibilidad (HA), como para aumentar la capacidad (throughput) de la entrada/salida de datos. Es importante destacar que, al crear un bonding, se genera una dirección MAC que es compartida por las NICs físicas en caso de configurar una IP en el bonding (esto ser verá en los ejemplos del routed mode).
Existen varios modos de funcionamiento en los bondings que son configurables. Entre ellos se pueden encontrar variantes de failovers (configuración de interfaces en activo-pasivo) y agregados de enlace, estáticos o mediante la utilización de protocolos como LACP:
- Modo 0 o Round Robin: Este es el comportamiento por defecto. Se envían los paquetes por todas las NICs de manera secuencial. Es muy importante que, si no se desea que el switch físico al que está conectado el host KVM detecte un error MAC FLAPPING, debido a que vea la misma dirección MAC (la del bonding) por dos puertos diferentes, y que esto haga incrementar enormemente la utilización de CPU de este, se deberá configurar en los switches un agregado de enlace estático.
- Modo 1 o Active-Backup: Solo una de las NICs es utilizada y, en caso de fallo, se comenzará a utilizar otra de las pertenecientes al mismo bonding, para lo cual se enviarán paquetes Gratuitous ARP para que los switches físicos actualicen el puerto al que enviar los paquetes, por lo que no se requiere ninguna configuración adicional en los switches externos.
- Modo 2 o XOR: Transmite balanceando entre los interfaces del bonding, basado en un Hash consistente en realizar la operación XOR entre la dirección MAC origen y la MAC destino. Al igual que con el método Round Robin, se ha de configurar un agregado estático en los switches externos a los que está conectado el Host KVM.
- Modo 3 o Broadcast: Este método hace que se envíen todos los paquetes por todos los interfaces externos que tenga definido el bonding, por lo que solo aporta HA, no balanceo de carga. Además introduce paquetes duplicados y también se propicia el problema del HOST FLAPPING.
- Modo 4 o 802.3ad (LACP): En los switches externos que conectan las interfaces del KVM, también se deberá configurar el protocolo LACP.
- Modo 5 o Adaptive transmit load balancing (TLB): El tráfico saliente se distribuye atendiendo al nivel de carga de las interfaces físicas asociadas al bonding, mientras que el tráfico entrante se recibe por solamente uno de los interfaces (aunque si falla se empezará a recibir por otro interfaz). Existe una diferencia adicional muy importante, y es que el modo TLB reescribe la MAC origen del bonding cambiándola por la MAC del interfaz utilizado para la transmisión, con lo que se evitan los flapeos de MAC en los switches. El único problema puede venir dado en que algunos routers/servidores no "encajen" bien que los paquetes de una IP le lleguen con varias MACs diferentes; en esos casos este método no se debería utilizar. Con este modo se consigue failover y balanceo de carga de tráfico de salida.
- Modo 6 o Adaptive load balancing (ALB): Es igual al método TLB pero con un balanceo de carga también para el tráfico recibido, el cual es obtenido mediante la negociación ARP, para ello intercepta las los ARP Replies que transcurren desde el bonding y reescribe la MAC origen, incluyendo una de las MACs de las interfaces físicas. Al igual que TLB, no requiere ninguna configuración adicional en los switches externos.
Como se puede ver, los métodos active-backup, broadcast y TLB no permiten el balanceo de carga. Por su parte ALB modifica las MACs origen, y tanto Round Robin como XOR no tienen una interacción con el switch que garantice la consistencia del agregado, es por ello que el método recomendado es LACP.
No obstante, hay que tener también presente que para configurar en los switches que conectan a los KVMs, los agregados estáticos (modos Round-Robin y XOR) o los agregados dinámicos (LACP), ambas interfaces deben pertenecer a un mismo switch físico, o a un stack de switches (ver entrada TRILL, SPB, VXLAN, NVGRE, EVI, OTV, EVB, VNTag: nuevas soluciones para antiguos problemas donde se comenta más en detalle esta necesidad a la hora de crear los agregados en los switches), por lo que en ciertas ocasiones puede ser aconsejable utilizar otros modos de bonding.
Para finalizar con respecto a los bondings, es importante tener en cuenta el método de monitorización del enlace, que puede hacerse de dos modos (son mutuamente excluyentes):
- Monitorizando el Media Independent Interface (miimon): Esta es la monitorización pura del estado del enlace a nivel local, no se prueba la conectividad a través de él.
- Monitorizando de ARPs: Con esta monitorización se envían request ARP a una serie de IPs definidas por configuración (se debe tener cuidado al elegir dichas IPs) y se espera su respuesta. Este método tiene la ventaja de que prueba no solo el estado del enlace del host, sino directamente la conectividad entre el host y el switch. Con algunos tipos de bonding este método puede ser contraproducente, ya que si todas las respuestas de los ARP request llegan al mismo interfaz del bonding, y el resto no recibe nada, estos últimos serían marcados como "caídos".
También hay que pensar que con LACP se prueba en cierta medida la conectividad, al existir la necesidad de interacción entre el Host y el switch para formar el bonding.
Si se añade un bonding, el anterior esquema se vería del siguiente modo:
Figura 2 - HA de enlaces mediante bonding
Utilización de VLANs
Otro punto a tener en cuenta es la utilización de VLANs para segmentar las redes. Aquí hay dos vertientes, la más común es que el tag de VLAN lo realice el KVM, de manera que la máquina virtual tenga conectado su vNIC (TAP) a un "puerto de acceso" con una VLAN específica. La otra opción es que sea la propia máquina virtual la que realice el tag de VLANs, en cuyo caso habría que simular una conexión "trunk de VLANs" (802.1q) a través de la vNIC. En ambos casos, en el switch, se deberán configurar los interfaces que conectan al Host KVM en modo 802.1q.
Cuando se desea utilizar VLANs y que el tag lo realice el KVM, se deben crear subinterfaces dentro de cada una de las interfaces físicas que conectan con el exterior, cada una de ellas asociada a un tag de VLAN. Una vez que se tiene una subinterfaz por cada ID de VLAN, a cada una de estas subinterfaces se le asocia un bridge, al cual se conectarán las vNICs (TAPs) de las máquinas virtuales.
El siguiente esquema representa la configuración anterior:
Figura 3 -VLANs marcadas por el Host KVM
Dentro del bridge el tráfico ya no estará marcado con la ID de VLAN, por lo que se podría ver a este bridge como un "puerto de acceso" si se piensa en la configuración tradicional de un switch (o más bien un HUB conectado a un puerto de acceso, ya que los puertos de acceso serían propios TAPs).
En el caso de utilizar bondings, las subinterfaces irían creadas en los propios bondings, de este modo:
Figura 4 -VLANs marcadas por el Host KVM con bonding
Para poder enviar-recibir tráfico por la VLAN nativa (la que no dispone de tag), se debería vincular un bridge directo al bond/interfaz (no a las subinterfaces), ya que es ahí donde se recoge ese tráfico.
Si lo que se desea es que las propias máquinas virtuales realicen el tag no se deberán crear las subinterfaces en las NICs físicas (o en los bondings, de ser utilizados), si no que se conectará directamente el bridge a las interfaces externas y se creará en el propio bridge una subinterfaz por cada tag de VLAN. Por último, se agregarán los TAPs directamente al bridge, no a las subinterfaces del bridge, de manera que el tráfico que le llega a la máquina virtual mantendrá aún los tag de VLANs, con lo que se consigue un pseudo "trunk de VLANs" en cada uno de las vNICs conectadas al bridge.
Las subinterfaces se realizan sobre el bridge, ya que cuando se forman sobre las interfaces o bondings, lo que se logra, es que se eliminen los tags de las VLANs, mientras que el comportamiento buscado es que los tags lleguen hasta la máquina virtual.
Este tipo de conexión es mutuamente excluyente del anterior, es decir, no se pueden compatibilizar con una misma conexión física/bonding.
Para clarificar esto, se expone el siguiente diagrama:
Figura 5 -VLANs marcadas por la máquina virtual
Es importante destacar que con algunos drivers de red para las máquinas virtuales el protocolo 802.1q puede dar fallo, siendo el driver "virtio" el recomendado para este tipo de conexión.
Ejemplos de configuración
Se van a mostrar tres modos de configuración de los bridges y bondings (los VTAPs se generarán siempre con la herramienta de creación de VMs):
- Configuración manual
- Utilización de API libvirt
- Herramienta CLI (virsh)
- Herramienta GUI (virt-manager)
Libvirt es un conjunto de herramientas que permiten interactuar con los procesos de virtualización. Se utilizan ficheros XML, donde se almacenan los datos referentes a cada uno de los componentes, de manera que se simplifica la comprehensión y el manejo de estos. Cuenta con comandos CLI así como una herramienta GUI.
En todos los casos se va a proceder a configurar un despliegue con bonding LACP y VLANs (tag incluido por el Host, no por las VMs), es decir, este esquema ya visto anteriormente (en este esquema aparecen los elementos configurados durante este ejemplo):
Figura 6 -Esquema general configurado en el ejemplo manual
Todas las configuraciones se realizarán sobre un SO CentOS 6.5 con instalación la instalación mínima de paquetes. A parte de la configuración mínima, se deberán instalar también los siguientes paquetes para el soporte KVM:
yum install kvm qemu-kvm libvirt virt-manager libguestfs-tools libvirt-python python-virtinst
Configuración manual
Para la creación manual se han de seguir los siguientes pasos antes de la creación de la VM:
- Creación del bonding
- Creación de los subinterfaces bonding para las VLANs
- Creación de bridges para las subinterfaces del bonding
Para crear el bonding LACP, se han de modificar los ficheros de las interfaces que pertenezcan al bonding, en este primer ejemplo eth1 y eth2. Para editar los ficheros se puede utilizar la herramienta VI:
vi /etc/sysconfig/network-scripts/ifcfg-eth1
El fichero deberá contener lo siguiente:
BOOTPROTO=none
DEVICE=eth1
HWADDR=00:0C:29:E3:0F:F2
MASTER=bond0
## jumbo frames desactivadas
#MTU=9000
NM_CONTROLLED=no
NOZEROCONF=yes
ONBOOT=yes
SLAVE=yes
TYPE=Ethernet
|
Como se puede ver, se han vinculado el interfaz a un bond (modificador SLAVE), en concreto al bond0 (modificador MASTER), el cual será creado más tarde.
Se deberá ajustar la dirección MAC (HWADDR) dependiendo de la eth utilizada. Para conocerla se puede hacer uso del commando ifconfig:
ifconfig eth1
Mediante el parámetro NM_CONTROLLED, se especifica que el demonio NetworkManager no controle el interfaz (ya que la configuración es preferible que se haga de modo directo, sin modificaciones por parte de este Software).
Se realizará el mismo procedimiento con ifcfg-eth2.
Cuando los miembros (slaves) del bonding ya están configurados, se puede crear el fichero de configuración del bonding, bond0 en este caso:
vi /etc/sysconfig/network-scripts/ifcfg-bond0
En el fichero deberá figurar una configuración parecida a la siguiente:
BOOTPROTO=none
DEVICE=bond0
IPV6INIT=no
## Optional, use for jumbo frames
if needed
#MTU=9000
NM_CONTROLLED=no
NOZEROCONF=yes
ONBOOT=yes
BONDING_OPTS="miimon=100
mode=802.3ad lacp_rate=1"
|
En la configuración de BONDING_OPTS se especifica el tipo de bonding (mode 4, o LACP), así como la monitorización a utilizar (miimon). También se puede indicar si se utilizará LACP fast (lacp_rate=1), que es aquel en el que las PDUs de LACP se transmiten cada segundo o LACP slow (lacp_rate=0), donde se transmiten cada 30 segundos.
Con lo anterior ya se habría generado la configuración suficiente para tener este esquema:
Figura 7 -Esquema con bond configurado
Una vez configurado el bonding, se procede a la configuración de sus subinterfaces, las cuales darán la conectividad de las VLANs. Para ello se crearán los ficheros de las subinterfaces de manera similar. Este es el ejemplo para configurar la VLAN 125:
vi /etc/sysconfig/network-scripts/ifcfg-bond0.125
DEVICE=bond0.125
ONBOOT=yes
TYPE=Ethernet
BOOTPROTO=static
VLAN=yes
BRIDGE=br125
|
En el subinterfaz ya se le vincula al bridge (BRIDGE=br125) aunque todavía no se ha creado.
Con las subinterfaces, el diagrama quedaría del siguiente modo:
Figura 8 - Esquema con bond y VLANs configurados
Antes de crear los bridges vinculados a los subinterfaces, se instalarán los paquetes bridge-utils:
yum install bridge-utils
Con estas herramientas también se pueden crear los bridges directamente mediante comando (brctl addbr) pero para este ejemplo se continuará con la edición de ficheros ya que esto hace las configuraciones persistentes a los rebotes del Host KVM.
Para generar los bridges, se han de crear los ficheros de configuración asociados, por ejemplo, para crear el bridge br125:
vi /etc/sysconfig/network-scripts/ifcfg-br125
DEVICE=br125
ONBOOT=yes
TYPE=Bridge
VLAN=yes
# En este ejemplo no se pone IP al bridge
# IPv4
#GATEWAY=
#IPADDR=
#NETMASK=
NM_CONTROLLED=no
NOZEROCONF=yes
## jumbo frames deshabilitadas
#MTU=9000
|
Con el bonding, las subinterfaces y los bridges configurados, se puede reiniciar el servicio de red, para que se hagan efectivos todos los cambios:
service network restart
También se puede utilizar el siguiente comando que activa el nuevo interfaz:
ifup br125
Tras el reinicio, el esquema siguiente (preparado ya para la conexión de VMs) se hará efectivo:
Figura 9 - Esquema con bond, VLANs y bridges de conexión configurados
Si no aparecen errores en el reinicio del servicio, ya se podría comprobar cómo la configuración anterior ha surgido efecto, por ejemplo comprobando el bonding con el siguiente comando:
cat /proc/net/bonding/bond0
La salida de este comando debería ser algo parecido a lo siguiente:
[root@kvm1 ~]#
cat /proc/net/bonding/bond0
Ethernet Channel
Bonding Driver: v3.6.0 (September 26, 2009)
Bonding Mode:
IEEE 802.3ad Dynamic link aggregation
Transmit Hash
Policy: layer2 (0)
MII Status: up
MII Polling
Interval (ms): 100
Up Delay (ms): 0
Down Delay (ms):
0
802.3ad info
LACP rate: fast
Aggregator
selection policy (ad_select): stable
Active
Aggregator Info:
Aggregator ID: 1
Number of ports: 1
Actor Key: 0
Partner Key: 1
Partner Mac Address:
00:00:00:00:00:00
Slave Interface:
eth1
MII Status: up
Speed: Unknown
Duplex: Unknown
Link Failure
Count: 0
Permanent HW addr: 00:0c:29:e3:0f:de
Aggregator ID: 1
Slave queue ID:
0
Slave Interface:
eth2
MII Status: up
Speed: Unknown
Duplex: Unknown
Link Failure
Count: 0
Permanent HW
addr: 00:0c:29:e3:0f:e8
Aggregator ID: 2
Slave queue ID:
0
|
También se puede comprobar la correcta creación de los bridges. En este ejemplo se han creado dos subinterfaces en el bonding, una para la VLAN 125 (aparecida en el ejemplo anterior) y otra para la VLAN 126. se pueden revisar con el comando:
brctl show
Su salida sería similar a la siguiente:
[root@kvm1 ~]#
brctl show
bridge name bridge id STP enabled interfaces
br125 8000.000c29e30fde no bond0.125
br126 8000.000c29e30fde no bond0.126
|
El Spanning-Tree se deshabilitará, ya que los enlaces redundantes que se van a tener son agregados mediante LDAP.
En este punto, ya se puede crear una máquina virtual de pruebas (sin disco) y asociarla a la VLAN 125 mediante el uso del br125. Para ello se puede utilizar el comando virt-install. Este paso no es estrictamente manual, ya que se hace uso de este Software.
virt-install --name=VM_test_manual --arch=x86_64 --vcpus=1 --ram=512 --os-type=linux --hvm --connect=qemu:///system --network bridge:br0.125 --vnc --noautoconsole --nodisk --boot cdrom
Una vez creada, se habrá generado una interfaz TAP (en este caso nombrada como vnet0, pero este nombre no es para siempre, cada vez que se encienda la máquina se elegirá un nombre para ella) vinculada al bridge:
[root@kvm1 ~]#
brctl show
bridge name bridge id STP enabled interfaces
br125 8000.000c29e30fde no bond0.125
vnet0
br126 8000.000c29e30fde no bond0.126
|
En el siguiente esquema se muestra la conectividad llegados a este punto:
Figura 10 - Esquema final del ejemplo de configuración manual
Un punto importante a destacar es que la dirección MAC que utiliza el Host para la vNIC (vnet0) de la máquina virtual, y que es la que realmente se utiliza para enviar los paquetes, no es la misma que el Sistema Operativo instalado en la máquina virtual detecta. Esto es una limitación del uso de interfaces TAP.
Este es un ejemplo de ello. En esta primera captura se puede ver la dirección MAC que ve el SO de una máquina virtual:
$ ifconfig eth0
eth0
Link encap:Ethernet HWaddr
52:54:00:BC:29:C7
inet6 addr: fe80::5054:ff:febc:29c7/64 Scope:Link
UP BROADCAST RUNNING MULTICAST
MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX
bytes:1434 (1.4 KiB)
Interrupt:10 Base address:0x2000
|
Y aquí esa misma interfaz vista desde el Host KVM. Se puede apreciar como el inicio de la dirección MAC es "FE" en lugar de "52"
[root@kvm3 ~]# ifconfig vnet0
vnet0
Link encap:Ethernet HWaddr
FE:54:00:BC:29:C7
inet6 addr: fe80::fc54:ff:febc:29c7/64 Scope:Link
UP BROADCAST RUNNING MULTICAST
MTU:1500 Metric:1
RX packets:9 errors:0 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:1434 (1.4 KiB) TX
bytes:468 (468.0 b)
|
Para que el Sistema Operativo de la máquina virtual y el del Host KVM "vean" la misma dirección MAC se deberá utilizar el método del "driver Macvtap" en lugar de la conexión mediante bridges y TAP.
Configuración con libvirt (CLI)
La herramienta a utilizar para configurar desde el CLI la conectividad de las VMs es el comando virsh.
Se puede ejecutar en una sola línea o entrar en un "modo interactivo", que puede ser útil, ya que con la tecla tabulador se autocompletan las posibles opciones de ejecución. Para ilustrar esto, se presentan dos modos de recibir toda la información de la máquina virtual creada en el punto anterior.
En usa sola línea:
virsh dumpxml VM_test_manual
En "modo interactivo":
[root@kvm1 ~]#
virsh
Welcome to
virsh, the virtualization interactive terminal.
Type: 'help' for help with commands
'quit' to quit
virsh # dumpxml
VM_test_manual
|
NOTA: Si no se recuerda el nombre de la VM se puede ejecutar "list --all"
Con los anteriores comandos se muestra por pantalla el XLM de configuración de la VM. Se puede observar cómo también figura la configuración de red de dicha máquina:
...
<interface type='bridge'>
<mac address='52:54:00:31:34:e3'/>
<source bridge='br125'/>
<target dev='vnet0'/>
<alias name='net0'/>
<address type='pci' domain='0x0000'
bus='0x00' slot='0x03' function='0x0'/>
</interface>
...
|
Esto puede ser útil a la hora de conocer el/los interfaz/es TAP de la máquina virtual. También se puede comprobar cómo la dirección MAC coincide con la mostrada por el comando ifconfig, donde también se pueden consultar las estadísticas de red para esa interfaz concreta:
[root@kvm1 ~]#
ifconfig vnet0
vnet0 Link encap:Ethernet HWaddr FE:54:00:31:34:E3
inet6 addr:
fe80::fc54:ff:fe31:34e3/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500
Metric:1
RX packets:433 errors:0 dropped:0
overruns:0 frame:0
TX packets:6 errors:0 dropped:0
overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:183912 (179.6 KiB) TX bytes:468 (468.0 b)
|
El comando virsh también puede ser utilizado para el manejo del estado de las VMs (apagado, encendido, borrado,....).
La creación de las interfaces bonding, las subinterfaces y los bridges utilizando el comando virsh, también se puede hacer de dos modos, una mediante la utilización propia de comandos de creación (como virsh iface-bridge "xxx" "yyy") o importando ficheros XML previamente generados. En los ejemplos se ha seguido el segundo camino.
Para tener una idea de cómo son los ficheros XML, se pueden consultar los de los bonding y bridges generados en el anterior apartado de manera manual.
Primero se pueden ver todos los interfaces utilizados del siguiente modo:
[root@kvm1 ~]#
virsh iface-list --all
Name State MAC Address
--------------------------------------------
bond0 active
br125 active fe:54:00:31:34:e3
br126 active ba:7c:dd:d5:e8:1b
eth0 active 00:0c:29:e3:0f:d4
eth3 active 00:0c:29:e3:0f:06
lo active 00:00:00:00:00:00
|
Una vez se tiene claro el nombre, se puede extraer el XML:
[root@kvm1 ~]#
virsh iface-dumpxml br125
<interface
type='bridge' name='br125'>
<protocol family='ipv6'>
<ip
address='fe80::8cfc:44ff:fedf:82a3' prefix='64'/>
</protocol>
<bridge>
<interface type='ethernet'
name='vnet0'>
<mac
address='fe:54:00:31:34:e3'/>
</interface>
</bridge>
</interface>
|
En este ejemplo se creará un nuevo bonding (bond100) con los interfaces físicos eth4 y eth5, al cual se asociarán dos VLANs la 555 y la 556.
Para la configuración del bonding, se genera un fichero llamado "make_bond100.xml":
vi make_bond100.xml
<interface type='bond' name='bond100'>
<start mode="onboot"/>
<bond mode="802.3ad">
<interface type='ethernet'
name='eth4'>
<mac
address='00:0C:29:E3:0F:06'/>
</interface>
<interface type='ethernet'
name='eth5'>
<mac
address='00:0C:29:E3:0F:FC'/>
</interface>
</bond>
</interface>
|
En el XML figuran tanto las interfaces físicas utilizadas, como el tipo de bonding (con esto último puede producirse un problema, el cual se mostrará más adelante).
<interface type='bridge' name='br999'>
<bridge><interface type='bond' name='bond100'>
<start mode="onboot"/>
<bond mode="802.3ad">
<interface type='ethernet' name='eth4'>
<mac address='00:0C:29:E3:0F:06'/>
</interface>
<interface type='ethernet' name='eth5'>
<mac address='00:0C:29:E3:0F:FC'/>
</interface>
</bond>
</interface>
</bridge>
</interface>
|
El anterior fichero crearía a la vez el bonding y el bridge conectado a él.
Siguiendo con el ejemplo en el que se utilizan VLANs marcadas por el Host KVM, una vez que se tiene el fichero de configuración del bonding, se realiza la "definición" del interfaz a partir de él:
Siguiendo con el ejemplo en el que se utilizan VLANs marcadas por el Host KVM, una vez que se tiene el fichero de configuración del bonding, se realiza la "definición" del interfaz a partir de él:
[root@kvm1 ~]#
virsh iface-define make_bond100.xml
Interface br100
defined from /root/
|
Tras ser definido ya aparecerá en la lista de interfaces, aunque todavía en modo inactivo:
[root@kvm1 ~]#
virsh iface-list --all
Name State MAC Address
--------------------------------------------
br0 active 00:0c:29:e3:0f:de
br100 inactive
br125 active 00:0c:29:e3:0f:de
br126 active 00:0c:29:e3:0f:de
eth0 active
00:0c:29:e3:0f:d4
eth3 active 00:0c:29:e3:0f:f2
lo active 00:00:00:00:00:00
|
Para hacerlo efectivo se ejecutará el siguiente comando
virsh iface-start bond100
Los anteriores comandos generará también el correspondiente fichero de configuración (similar al creado en el punto anterior):
[root@kvm1 ~]#
cat /etc/sysconfig/network-scripts/ifcfg-bond100
DEVICE=bond100
ONBOOT=yes
BONDING_OPTS="'mode=802.3ad'"
|
Como se puede ver, en las opciones se incluyen las comillas simples ( ' ) a parte de las comillas dobles ( " ). Tal vez sea ese el motivo de que, si las comillas simples (') no se eliminan, el bonding no toma las opciones incluidas en la configuración, con lo que toma las que tiene por defecto (balanceo round-robin).
Esto se puede comprobar mediante el comando cat /proc/net/bonding/bond100 de manera similar a antes, o simplemente consultando el balanceo mediante este otro comando:
[root@kvm1 ~]#
cat /sys/class/net/bond100/bonding/mode
balance-rr 0
|
Para solventar este problema, como se ha dicho, simplemente hay que eliminar las comillas simples, pero se puede aprovechar para incluir el resto de modificadores antes vistos:
[root@kvm1 ~]# cat /etc/sysconfig/network-scripts/ifcfg-bond100
DEVICE=bond100
ONBOOT=yes
BONDING_OPTS="miimon=100 mode=802.3ad lacp_rate=1"
|
Tras este cambio, se ha de bajar y subir el interfaz:
[root@kvm1 ~]#
ifdown bond100
[root@kvm1 ~]#
ifup bond100
|
Con esto ,el bonding ya será LACP:
[root@kvm1 ~]#
cat /sys/class/net/bond100/bonding/mode
802.3ad 4
|
Con el bonding correctamente creado, se genera el fichero XML para las subinterfaces de las VLANs y los bridges asociados. En este caso, al contrario que en la configuración manual vista en el anterior punto, no es necesario crear la subinterfaz y más tarde el bridge, se puede hacer en un solo fichero:
<interface
type="bridge" name="br555">
<start mode="onboot"/>
<bridge>
<interface type="vlan" name="bond100.555">
<vlan tag="555">
<interface
name="bond100"/>
</vlan>
</interface>
</bridge>
</interface>
|
El proceso se repite para br556, pero añadiendo este al bond100.556 y al tag de VLAN 556.
Con los ficheros de los dos bridges+subinterfaces se procede a su "definición":
[root@kvm1 ~]#
virsh iface-define make_br555.xml
Interface br555
defined from /root/
[root@kvm1 ~]#
virsh iface-define make_br556.xml
Interface br556
defined from /root/
|
[root@kvm1 ~]#
virsh iface-start br555
Interface br555
started
[root@kvm1 ~]#
virsh iface-start br556
Interface br556
started
|
[root@kvm1 ~]#
virsh iface-list
Name State MAC Address
--------------------------------------------
bond0 active 00:0c:29:e3:0f:f2
bond100 active 00:0c:29:e3:0f:10
br125 active 00:0c:29:e3:0f:f2
br126 active
00:0c:29:e3:0f:f2
br555 active 00:0c:29:e3:0f:10
br556 active 00:0c:29:e3:0f:10
eth0 active 00:0c:29:e3:0f:d4
eth3 active 00:0c:29:e3:0f:06
lo active 00:00:00:00:00:00
|
[root@kvm1 ~]#
brctl show
bridge name bridge id STP enabled interfaces
br125 8000.000c29e30ff2 no bond0.125
vnet0
br126 8000.000c29e30ff2 no bond0.126
br555 8000.000c29e30f10 no bond100.555
br556 8000.000c29e30f10 no bond100.556
virbr0 8000.5254001f721a yes virbr0-nic
|
Con este comando, se puede apreciar cómo ha surgido un nuevo bridge llamado virbr0. Este bridge es auto-generado para dar soporte a la red virtual "default" que proporciona conectividad L3 mediante NAT. Esto será comentado más adelante en el apartado de conectividad L3 - routed mode.
virt-install --name=VM_test_LIBVIRT --arch=x86_64 --vcpus=1 --ram=512 --os-type=linux --hvm --connect=qemu:///system --network bridge:br555 --vnc --noautoconsole --nodisk --boot cdrom
y comprobar la conectividad de su nueva vNIC (TAP) llamada vnet1:
[root@kvm1 ~]#
brctl show
bridge name bridge id STP enabled interfaces
br125 8000.000c29e30ff2 no bond0.125
vnet0
br126 8000.000c29e30ff2 no bond0.126
br555 8000.000c29e30f10 no bond100.555
vnet1
br556 8000.000c29e30f10 no bond100.556
virbr0 8000.5254001f721a yes virbr0-nic
|
Configuración con libvirt (GUI)
El método de configuración por GUI puede parecer el más simple, pero lo cierto es que pueden presentarse diversos errores a la hora de la configuración y/o activación de interfaces por este método, por lo cual en ocasiones puede ser preferible las configuraciones manuales o mediante CLI vistas anteriormente.
Para poder utilizar una interfaz gráfica que proporciona virt-manager, se deben contar con los paquetes X Windows. Estos se pueden instalar de la siguiente manera (recomendable reiniciar la máquina tras ello):
yum groupinstall "X Window System"
Puede que tras el rebote posterior a la instalación de los paquetes X, durante el propio reinicio, se pidan configuraciones adicionales. Estas pueden ser obviadas, para lo cual habrá que comprobar el proceso de reinicio. Si no se tiene un monitor esto se puede hacer mediante puerto serie, iLO (o similar).
Junto con esto, si se accede remotamente al Host KVM por SSH, en lugar de tener conectado un monitor y teclado, se deberá tener instalado (y estar ejecutándose), en la máquina desde la que se realiza la conexión SSH, un servidor de X Window remoto, como por ejemplo Xming. Estos servidores X remotos permiten mostrar aplicaciones gráficas de manera local pero que son ejecutadas remotamente (en el caso abordado en el Host KVM).
Para que el servidor X puede recibir la información desde el Host KVM remoto por medio de SSH, se debe permitir el "X11 forwarding" antes de iniciar la conexión. A continuación se puede ver un ejemplo para su activación en Putty / Kitty en el menú Connection > SSH > X11:
Figura 11 - Activación de X11 forwarding en Kitty
Si lo anterior se ha hecho correctamente, una vez realizada la conexión SSH con "X11 forwarding" habilitado, se puede ejecutar el comando virt-manager. Si los paquetes no han sido instalados, o el Host KVM no tiene acceso al servidor X remoto aparecerá un error parecido al siguiente:
[root@kvm1 ~]#
virt-manager
Traceback (most
recent call last):
File
"/usr/share/virt-manager/virt-manager.py", line 383, in
<module>
main()
File
"/usr/share/virt-manager/virt-manager.py", line 286, in main
raise gtk_error
RuntimeError:
could not open display
|
Si todo está correcto, para configurar la conectividad desde la consola de virt-manager, hay que pulsar en Edit > Connection Details :
Figura 12 - Acceso a la configuración de conectividad de VMs en virt-manager
En la pestaña de "Network Interfaces" aparecen los interfaces con los que se cuenta hasta el momento:
Figura 13 - Visión global de interfaces de conexión ya creadas
Para crear un bonding con VLANs pero esta vez desde este interfaz gráfico, se deberá pulsar el símbolo "+" e ir creando los interfaces por el mismo orden que se ha visto hasta ahora: bonding -> Subinterfaces -> bridges.
El primer paso pues será la creación del bonding:
Figura 14 - Inicio de la creación de un bonding
Pulsando el botón "Configure" del "Bond mode" se pueden especificar las opciones de modo y monitor:
Figura 15 - Configuración del bonding
Con el método GUI sucede lo mismo que con el CLI (ya que utilizan los mismos recursos libvirt) en la creación de los bondings LACP, por lo que tras su creación por el GUI habrá que modificar manualmente en el fichero de configuración del bonding los parámetros, eliminando las comillas simples para que pueden hacerse efectivos de forma correcta.
Una vez configurado el Bond, se han de crear las subinterfaces. En el caso de GUI se puede seleccionar directamente la opción "VLAN":
Figura 16 - Inicio de la creación de VLANs
En la configuración se seleccionará el bond creado en el paso anterior:
Figura 17 - Configuración de VLAN
Las nuevas interfaces aparecerán sombreadas en el listado, ya que no se encuentran activas. Para activarlas se deberá pulsar el símbolo de play:
Figura 18 - Activación de interfaces
En este punto se pueden mostrar diversos errores. Si las interfaces no se activan, se puede intentar nuevamente pero mediante el comando virsh del modo visto anteriormente, o directamente reiniciando el Host KVM al finalizar la configuración del bonding, VLANs y bridges.
Por último, se han de configurar los bridges siguiendo el mismo procedimiento:
Figura 19 - Inicio de la creación de un bridge
Hay que recordar que existirá un bridge por cada VLAN. En el siguiente caso es el bridge que aporta conectividad a la VLAN 15:
Figura 20 - Configuración de un bridge
Al finalizar, y de haber activado los nuevos interfaces (a parte del br15 también se creó el br16 asociado a la VLAN 16) se podrá comprobar de su correcta configuración, tal y como se ha venido haciendo ("virsh list --all", "brctr show", "cat /proc/net/bonding/bond2", ...).
Si se desea crear una VM por el GUI para utilizar alguna de estas nuevas conexiones se deberán dar pulsar en "New" en la pantalla principal de virt-manager:
Figura 21 - Inicio de la creación de una máquina virtual
Tras indicar nombre y resto de parámetros de la máquina virtual, se llegará a la configuración de red, donde se podrá especificar el bridge al cual conectarla:
Figura 22 - Configuración de red en una nueva máquina virtual
En el desplegable aparecerán resaltadas todas las interfaces utilizables (bridges), mientras que sombreadas las que no se puedan conectar directamente a la máquina virtual:
Figura 23 - Lista de posibles interfaces a los que conectar una nueva máquina virtual
L3 - routed mode
El método "routed mode", o modo enrutado, tiene la ventaja de que el tráfico debe transcurrir por el "Host" que alberga las máquinas virtuales, lo cual puede ser útil para aplicar políticas de seguridad/firewall/NAT antes de salir del propio Host o a la hora de realizar troubleshooting. El método enrutado no es más que el método bridge, expuesto a continuación, al que se le añade una capa L3 entre la tarjeta física y el bridge virtual.
Este despliegue en muchos casos no será el ideal, ya que se pierde la visibilidad L2 desde fuera del Host KVM, pero ese aislamiento en un entorno "virtual" puede ser aprovechado por algunas arquitecturas.
Cuando se utiliza el routed mode, cada VM se encontrará contenida en una red virtual con su propia subred, y no será accesible desde el exterior a nivel L2, ya que entre esa red virtual y las redes externas existe un proceso del Host KVM que realiza routing.
Como ya se ha visto, el routed mode hace uso de los mismos conceptos vistos en el bridged mode, no obstante será necesario añadir una capa de routing, o lo que es lo mismo, asignar IPs a las interfaces involucradas y permitir el forwarding de paquetes entre ellas:
Utilización de VLANs
La utilización de VLANs no será la misma que en el modo bridge, ya que estas son utilizadas para segmentar a nivel 2, en en una configuración routed mode existe un nivel 3 entre las redes externas (donde antes estaban configuradas las VLANs) y las internas. Ya no se necesitan VLANs para separar el tráfico entre máquinas de diferentes redes, ya que cada red estará asociada a un bridge, el cual es segmentado por el propio routing del KVM:
Figura 25 - Representación simplificada del ejemplo routed mode
No obstante, puede suceder que se necesite enviar el tráfico hacia el exterior por diferentes VLANs a través de un trunk de VLANs, en lugar de hacerlo por una única red.
En el esquema anterior se mostraba la utilización de una única red/VLAN que conecta el Host KVM con una red externa. Por el contrario, en este diagrama se presenta la posibilidad de conectar varias VLANs (redes) al Host KVM:
Para obtener esta arquitectura en la que el Host KVM realice el tag de las VLANs hacia el exterior, se tendría que añadir el proceso de routing entre los bridges a los que se conectan las máquinas virtuales y los subinterfaces del bonding/interfaz (se puede repasar el apartado de bridged mode para comprender mejor la utilización de subinterfaces con el marcado de VLANs).
Las subinterfaces, ya sean del interfaz físico o del bonding, deberán tener asignadas las IPs del rango de cada VLAN a la que pertenezcan, mientras que el bridge interno al que se conectan las VMs deberá tener configurada una IP del rango de la red virtual (no tiene que coincidir con el direccionamiento de las VLANs al existir una capa L3 entre ellos), la cual será el default gateway de las VMs.
Por último, recordar que dentro de esta capa L3 también se pueden añadir servicios de firewalling, NAT o monitorización.
Ejemplos de configuración
Se presentan, al igual que en apartado anterior, tres métodos de configuración, uno manual (para comprender el funcionamiento interno), y otros dos mediante libvirt, que facilita la configuración pero oculta en cierta medida los cambios producidos en el Host.
La arquitectura a implementar en los ejemplos utilizará bondings. También se configurará que el Host realice el marcado 802.1q (tag de VLANs) del tráfico.
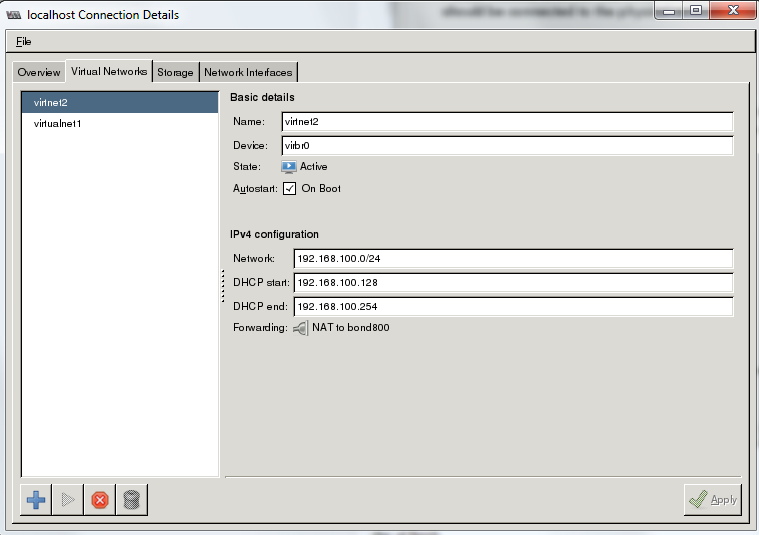
Se ha de tener en cuenta un aspecto adicional al haber utilizado previamente (en el apartado anterior) libvirt para la configuración de bridges. Al utilizar virsh y virt-manager para crear los componentes de red, también se crea de manera adicional (llamada default) como ya se ha visto, asociada al bridge virbr0:
[root@kvm1 ~]# brctl show
bridge name bridge id STP enabled interfaces
br125 8000.000c29e30ff2 no bond0.125
vnet0
br126 8000.000c29e30ff2 no bond0.126
br555 8000.000c29e30f10 no bond100.555
br556 8000.000c29e30f10 no bond100.556
virbr0 8000.5254001f721a yes virbr0-nic
|
[root@kvm1 ~]# virsh net-list
Name State Autostart Persistent
--------------------------------------------------
default active yes yes
|
NOTA: el comando virsh net-list será explicado más adelante, durante la configuración CLI con libvirt
Esta red "default" es un virtual network (routed mode) en el que se hace NAT al tráfico saliente. Como este tipo de redes se van a discutir dentro de los ejemplos de configuración, se cree conveniente borrar esta red por defecto para no llevar a confusión:
virsh net-destroy default
Configuración manual
La configuración se basa en cinco pasos:
- Creación de conexión L2 externa (bonding) del bridge interno para la conexión de VMs
- Activación de IP forwarding en el Host
- Configuración de políticas L3 (y NAT si se necesitase)
- Configuración de rutas
- Configuración de servicios añadidos (por ejemplo DHCP y DNS).
El primer paso se generará un bonding para garantizar el HA de los enlaces. Tras incluir los modificadores SLAVE y MASTER en las interfaces físicas (ethx), se deberá crear el fichero del bonding:
vi /etc/sysconfig/network-scripts/ifcfg-bond50
BOOTPROTO=static
IPADDR=1.0.1.95
NETMASK=255.255.255.0
SUBNET=1.0.1.0
HWADDR=56:EF:25:79:B7:BF
DEVICE=bond50
IPV6INIT=no
## Optional, use for jumbo frames if needed
#MTU=9000
NM_CONTROLLED=no
NOZEROCONF=yes
ONBOOT=yes
BONDING_OPTS="miimon=100 mode=802.3ad
lacp_rate=1"
|
Además, como se desea que se realice tag de VLANs (a parte de la conexión por la VLAN nativa), se han de crear los subinterfaces en el bonding, por ejemplo si se quisiesen crear la VLAN 66 y 67, se necesitaría incluir estos ficheros:
vi /etc/sysconfig/network-scripts/ifcfg-bond50.66
DEVICE=bond50.66
ONBOOT=yes
TYPE=Ethernet
BOOTPROTO=static
VLAN=yes
IPADDR=66.66.66.95
NETMASK=255.255.255.0
SUBNET=66.66.66.0
|
vi /etc/sysconfig/network-scripts/ifcfg-bond50.67
DEVICE=bond50.67
ONBOOT=yes
TYPE=Ethernet
BOOTPROTO=static
VLAN=yes
IPADDR=67.67.67.95
NETMASK=255.255.255.0
SUBNET=67.67.67.0
|
Para no complicar más el ejemplo de despliegue manual L3 no se utilizarán estas VLANs (ya que habría que configurar también para esas interfaces el forwarding, firewall, servicios añadidos, etc que se explicarán más adelante), por lo que tan solo se tomará como interfaz externa el bond50.
También, se debe crear un bridge interno del mismo modo que se ha visto anteriormente, con la diferencia que en este bridge se deberá configurar una IP (que será el default gateway de las VMs).
Se le nombró br50 pero se podría indicar en el nombre que es bridge de un "virtual network" nombrándolo, por ejemplo, como "virbr50".
Como se comentó anteriormente, cuando se configuran los servicios L3 en los bridges (se le asigna una IP, en este caso para la conectividad por la VLAN nativa), hay que tener cuidado con los cambios de MAC que se producen según los elementos que estén conectados a él, ya que el bridge selecciona como propia la MAC más baja de la de todos los elementos que estén conectados. Esto puede provocar que al conectar una VM a un bridge, la MAC de esta VM sea menor que todas las demás, por lo que en ese momento el bridge cambiará de MAC con lo que se perderán todas las conexiones que estuviesen establecidas en ese momento.
Como se comentó anteriormente, cuando se configuran los servicios L3 en los bridges (se le asigna una IP, en este caso para la conectividad por la VLAN nativa), hay que tener cuidado con los cambios de MAC que se producen según los elementos que estén conectados a él, ya que el bridge selecciona como propia la MAC más baja de la de todos los elementos que estén conectados. Esto puede provocar que al conectar una VM a un bridge, la MAC de esta VM sea menor que todas las demás, por lo que en ese momento el bridge cambiará de MAC con lo que se perderán todas las conexiones que estuviesen establecidas en ese momento.
Para asegurar el correcto uso de la dirección MAC se puede utilizar el parámetro HWADDR. Esta MAC puede ser la de una de las interfaces físicas que estén asociadas a él.
En el caso actual, no se dispone de ninguna interfaz física asociada, por lo que se puede tomar alguna de estas acciones:
En el caso actual, no se dispone de ninguna interfaz física asociada, por lo que se puede tomar alguna de estas acciones:
- Crear una NIC virtual (o también llamada dummy) y asociarla al bridge simplemente para que este pueda heredar su MAC, por lo que esta quedará definida estáticamente.
- Asignar una dirección MAC a la interfaz bridge mediante el parámetro MACADDR. Es importante distinguir entre el parámetro MACADDR, el cual asigna una dirección MAC al interfaz, y el parámetro HWADDR, que sirve para asegurarse de que la interfaz utiliza la MAC deseada.
Para el primer caso, esa interfaz dummy no será otra cosa que una interfaz TAP. Para crear esta interafaz TAP, se puede crear un script destinado a ello, tal y como se explica en esta web, se puede utilizar un Software llamado tunctl, así como creando un nuevo fichero de interfaz, de modo que no exista problema de persistencia tras reinicios.
El segundo caso, se le asigna directamente la dirección MAC en el fichero del interfaz bridge. Para generar direcciones MAC de manera aleatoria se pueden utilizar alguno de los scripts que se pueden encontrar en Internet o, mediante una manera más simple, haciendo uso de una página Web que proporcione ese servicio. En ejemplo sería esta web.
vi /etc/sysconfig/network-scripts/ifcfg-br50
DEVICE=br50
TYPE=Bridge
BOOTPROTO=static
MACADDR=47:55:81:C9:47:EB
IPADDR=5.5.5.1
NETMASK=255.255.255.0
SUBNET=5.5.5.0
ONBOOT=yes
DELAY=0
|
En este caso, se configura una dirección IP que será el default gateway de las máquinas que estén conectados a este bridge.
Para que se haga efectivo o se realiza el restar del servicio network o se utiliza el siguiente comando que activa el nuevo interfaz:
Para que se haga efectivo o se realiza el restar del servicio network o se utiliza el siguiente comando que activa el nuevo interfaz:
ifup br50
Para este ejemplo también se creó otro bridge br51 con IP 6.6.6.1.
Tras esta configuración ya se dispondrá de la arquitectura de conexión L2:
Tras esta configuración ya se dispondrá de la arquitectura de conexión L2:
Figura 27 - Representación de la conectividad L2 del ejemplo de configuración manual
Por otra parte, para que el Host KVM pueda realizar las funciones L3, se necesitará habilitar IP forwarding, para ello se deberá editar el siguiente fichero:
vi /etc/sysctl.conf
Se buscará y pondrá a "1" la siguiente línea:
net.ipv4.ip_forward = 1
|
Una vez modificado se deberá reiniciar el Host para que se haga efectiva la configuración (si fuese imposible reiniciarlo, se podría hacer uso del comando sysctl -p).
Con el IP forwarding habilitado (se debe reiniciar el servicio networking para que se haga hábil la anterior configuración), se han de configurar las reglas de routing. En este caso simplemente se incluirá una regla que permita reenviar el tráfico entre las VMs y las redes externas.
Como primer acercamiento, se deberá revisar las reglas IPTABLES (las que permiten hacer forwarding de paquetes y acciones de firewall) con el siguiente comando:
iptables --line-numbers -n -v -L
Un ejemplo de la salida de este comando puede verse a continuación:
| [root@kvm1
~]# iptables --line-numbers -n -v -L Chain INPUT (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 53 6422 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED 2 0 0 ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0 3 0 0 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0 4 1 52 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22 5 44 3432 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 0 0 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain OUTPUT (policy ACCEPT 57 packets, 8451 bytes)
num pkts bytes
target prot opt in out
source destination
|
- INPUT: Reglas para la recepción de paquetes por parte del Host KVM
- FORWARD: Reglas para el reenvío enrutado de paquetes
- OUTPUT: Reglas para la emisión de paquetes por parte del Host KVM
Como puede entreverse, las reglas que se han de modificar son las que modifican en comportamiento en el enrutado de paquetes, las del tipo FORWARD.
Por defecto existe una regla REJECT que no permite reenviar ningún paquete. Para modificar este comportamiento se deberán añadir reglas por delante de esta, o incluso borrar la regla REJECT.
La regla a añadir podría ser muy genérica, permitiendo el reenvío de todos los paquetes, sin depender de su origen o destino. Esta configuración sería más sencilla pero menos segura y flexible, por lo que se añadirán reglas específicas para las redes virtuales (las redes 5.5.5.0/24 y 6.6.6.0/24 que son con las que se generaron los bridges de ejemplo).
Para cada bridge se deberán crear una serie de reglas, por ejemplo, para permitir el forwarding de paquetes entre el bridge br50 y el exterior (y con el otro bridge), se deberán incluir:
- Regla que permita reenviar el tráfico desde el bridge externo, con origen cualquier IP, al bridge interno (br50) con destino la "red virtual" (5.5.5.0/24 en este ejemplo)
- Regla que permita reenviar el tráfico desde el bridge interno, con origen la red virtual, al bridge externo con destino cualquier IP
- Regla que permita reenviar el tráfico siempre que la interfaz origen y destino sea el bridge interno
- Regla de deniegue el reenvío desde cualquier interfaz/bridge (con origen cualquier IP) al bridge interno
- Regla de deniegue el reenvío desde el bridge interno (con cualquier IP) hacia cualquier interfaz/bridge
Como se puede ver la reglas 1 y 4 así como la 2 y 5 son antagónicas, pero ya que el orden en la configuración de las reglas importa, siempre que se de la regla 1 o 2 no se ejecutará la regla 4 o 5, del mismo modo que sucede en la configuración de cualquier firewall de red.
Estas reglas son genéricas, y podrían ser otras más o menos restrictivas, ya que tal vez se desee llegar a las redes externas, pero no al bridge 51 que también se ha creado en el mismo KVM. Se han elegido estas reglas, ya que son las que se crearán automáticamente cuando se realice, más adelante, al finalizar la explicación del método manual, el despliegue de "virtual networks" mediante libvirt.
Es importante hacer notar que si la red virtual fuese aislada (isolated), es decir, si no se desea conectarla a ninguna interfaz externa, las reglas 1 y 2 no han de incluirse.
Para generar las reglas de los puntos anteriores se deberán incluir los siguientes comandos (un comando por cada punto):
iptables -A FORWARD -i bond50 -o br50 -d 5.5.5.0/24 -j ACCEPT
iptables -A FORWARD -i br50 -o bond50 -s 5.5.5.0/24 -j ACCEPT
iptables -A FORWARD -i br50 -o br50 -j ACCEPT
iptables -A FORWARD -o br50 -j REJECT
iptables -A FORWARD -i br50 -j REJECT
Estas reglas son genéricas, y podrían ser otras más o menos restrictivas, ya que tal vez se desee llegar a las redes externas, pero no al bridge 51 que también se ha creado en el mismo KVM. Se han elegido estas reglas, ya que son las que se crearán automáticamente cuando se realice, más adelante, al finalizar la explicación del método manual, el despliegue de "virtual networks" mediante libvirt.
Es importante hacer notar que si la red virtual fuese aislada (isolated), es decir, si no se desea conectarla a ninguna interfaz externa, las reglas 1 y 2 no han de incluirse.
Para generar las reglas de los puntos anteriores se deberán incluir los siguientes comandos (un comando por cada punto):
iptables -A FORWARD -i bond50 -o br50 -d 5.5.5.0/24 -j ACCEPT
iptables -A FORWARD -i br50 -o bond50 -s 5.5.5.0/24 -j ACCEPT
iptables -A FORWARD -i br50 -o br50 -j ACCEPT
iptables -A FORWARD -o br50 -j REJECT
iptables -A FORWARD -i br50 -j REJECT
Los modificadores -i y -o indican las interfaces de entrada y salida respectivamente, mientras que -s y -d especifican IPs origen y destino.
Estos comandos generarán las reglas pertinentes en la tabla iptables:
| [root@kvm1
~]# iptables --line-numbers -n -v -L Chain INPUT (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 111 11862 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED 2 0 0 ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0 3 0 0 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0 4 1 52 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22 5 53 4134 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 0 0 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited 2 0 0 ACCEPT all -- bond50 br50 0.0.0.0/0 5.5.5.0/24 3 0 0 ACCEPT all -- br50 bond50 5.5.5.0/24 0.0.0.0/0 4 0 0 ACCEPT all -- br50 br50 0.0.0.0/0 0.0.0.0/0 5 0 0 REJECT all -- * br50 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable 6 0 0 REJECT all -- br50 * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable Chain OUTPUT (policy ACCEPT 39 packets, 7432 bytes)
num pkts bytes
target prot opt in out
source destination
|
Tras esto, se deberá "mover" al final de la lista la regla implícita de denegación del tráfico "FORWARD". Lo más facil para realizar este movimiento será borrar la regla que ya existe y volverla a crear, ya que al crearla se situará al final de la lista.
Lo primero es eliminar la política de denegación, para lo cual se debe saber la posición que ocupa (en este caso es facil, ya que será la primera de todas al no haber realizado este procedimiento con anterioridad):
| [root@kvm1
~]# iptables --line-numbers -n -v -L Chain INPUT (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 80 8894 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED 2 0 0 ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0 3 0 0 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0 4 1 52 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22 5 53 4134 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 0 0 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited 2 0 0 ACCEPT all -- bond50 br50 0.0.0.0/0 5.5.5.0/24 3 0 0 ACCEPT all -- br50 bond50 5.5.5.0/24 0.0.0.0/0 4 0 0 ACCEPT all -- br50 br50 0.0.0.0/0 0.0.0.0/0 5 0 0 REJECT all -- * br50 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable 6 0 0 REJECT all -- br50 * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable Chain OUTPUT (policy ACCEPT 10 packets, 1904 bytes)
num pkts bytes
target prot opt in out
source destination
|
Como era de esperar, la regla es la número 1, por lo cual se borra con el siguiente comando:
iptables -D FORWARD 1
Tras eso se vuelve a crear la regla:
iptables -A FORWARD -j REJECT
Y por último se verifica que el orden final es el esperado:
| [root@kvm1
~]# iptables --line-numbers -n -v -L Chain INPUT (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 420 39646 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED 2 0 0 ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0 3 0 0 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0 4 1 52 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:22 5 80 6240 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 0 0 ACCEPT all -- bond50 br50 0.0.0.0/0 5.5.5.0/24 2 0 0 ACCEPT all -- br50 bond50 5.5.5.0/24 0.0.0.0/0 3 0 0 ACCEPT all -- br50 br50 0.0.0.0/0 0.0.0.0/0 4 0 0 REJECT all -- * br50 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable 5 0 0 REJECT all -- br50 * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable 6 0 0 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable Chain OUTPUT (policy ACCEPT 4 packets, 496 bytes)
num pkts bytes
target prot opt in out
source destination
|
Con lo anterior, ya se han creado las reglas necesarias para realizar el forwarding del tráfico, pero las reglas iptables no son persistentes tras los reinicios del Host si no son convenientemente "guardados", ya que únicamente son almacenadas en memoria. Las reglas persistentes son guardadas en el siguiente fichero:
cat /etc/sysconfig/iptables
# Firewall configuration written by system-config-firewall
# Manual customization of this file is not recommended.
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
|
Como se puede apreciar, estas eran las reglas que aparecían en la lista antes de las modificaciones que se han realizado. Para hacer persistentes las reglas, se deberán añadir los comandos en este fichero (también moviendo el orden de la regla de REJECT general de FORWARDING):
vi /etc/sysconfig/iptables
# Firewall configuration written by system-config-firewall
# Manual customization of this file is not recommended.
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j
ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -i bond50 -o br50 -d 5.5.5.0/24 -j ACCEPT
-A FORWARD -i br50 -o bond50 -s 5.5.5.0/24 -j ACCEPT
-A FORWARD -i br50 -o br50 -j ACCEPT
-A FORWARD -o br50 -j REJECT
-A FORWARD -i br50 -j REJECT
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
|
También se puede hacer uso de herramientas que realizan este trabajo automáticamente, como iptables-save
Como se ha comentado, esta configuración de IPTABLES permite el reenvío de los paquetes (L3), pero si se necesitase realizar NAT de las IPs de las máquinas virtuales, se deberán introducir algunos cambios:
- La regla forward de entrada deberá ser modificada para solo permitir los paquetes que pertenezcan a conexiones ya establecidas, para ello los comandos serán estos (el único que cambia es el primero):
iptables -A FORWARD -i br50 -o bond50 -s 5.5.5.0/24 -j ACCEPT
iptables -A FORWARD -i br50 -o br50 -j ACCEPT
iptables -A FORWARD -o br50 -j REJECT
iptables -A FORWARD -i br50 -j REJECT
- Se deberá crear una regla adicional de NAT de origen
Para configurar los NATs se hace uso de las reglas PREROUTING y POSTROUTING de iptables. Las reglas PREROUTING permiten modificar los paquetes antes de la consulta de la tabla de enrutamiento, mientras que las reglas POSTROUTING se hacen efectivas tras dicha consulta.
Las reglas de NAT más habituales que se pueden desear en este tipo de entornos son:
- NAT de IP origen para el tráfico de salida de las máquinas virtuales
- Forwarding de puertos de la IP externa a la IP de una máquina virtual
El NAT de IP origen (SNAT), puede, a la vez utilizar una IP externa definida estáticamente, dinámicamente (también llamado enmascaramiento o MASQUERADING) o un pool de IPs.
Para el primer caso, en el que lo que se busca es utilizar una IP externa para "ocultar" las IPs de las máquinas virtuales (ya sea por re-aprovechamiento de direccionamiento, seguridad o por la necesidad de utilizar una IP pública), se han de configurar las reglas POSTROUTING pertinentes.
En el ejemplo que se está desarrollando, la IP "externa" que está configurada en el Host KVM es la 1.0.1.95, siendo la red la 1.0.1.0/24, por lo que las IPs de NAT deberán estar en este rango.
En el caso de querer utilizar la IP del Host KVM, como la IP origen de todo el tráfico de las máquinas virtuales (dela red 5.5.5.0/24), se podría hacer uso del siguiente comando:
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -j SNAT --to 1.0.1.95 ! -d 5.5.5.0/24
La última parte del comando "! -d 5.5.5.0/24" utiliza el modificado "!" para negar la red de destino 5.5.5.0/24. Con esto se consigue que se realice en NAT siempre que el destino NO sea la red 5.5.5.0/24. Si no se especifica esto, el NAT se realizaría con destino ANY, es decir, para todo el tráfico. Esto no sería problema pero con esta modificación se asegura que el tráfico que dentro de la red 5.5.5.0/24 no se NATea.
También se podrá utilizar otra IP que no sea la propiamente configurada en el bonding pero en ese caso el Host KVM no contestaría a las peticiones ARP de la dirección NAT, a no ser que tome consciencia de que dicha IP es mantenida por el mismo.
Para que se produzcan las respuestas ARP, se le han de asignar las IPs utilizadas para el NAT, ya sea una única IP o un pool de ellas, para lo cual se configurarán IP Alias en la interfaz externa (bond50 en este caso).
Contando con lo anterior, para asignar la IP de NAT 1.0.1.92 (no la .95 que es la del bond50), primero se creará la regla de NAT:
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -j SNAT --to 1.0.1.92 ! -d 5.5.5.0/24
y más tarde se creará el IP alias para esa IP. Para ello (en sistemas RHEL/CentOS que son los utilizados para los ejemplos) se copiará la configuración del interfaz bond50 en otro nuevo que se llamará bond50:0:
cp /etc/sysconfig/network-scripts/ifcfg-bond50 /etc/sysconfig/network-scripts/ifcfg-bond50:0
Tras ello se modificarán los parámetros DEVICE e IPADDR para adaptarlos a la nueva interfaz (IP Alias):
vi /etc/sysconfig/network-scripts/ifcfg-bond50:0
BOOTPROTO=static
IPADDR=1.0.1.92
NETMASK=255.255.255.0
SUBNET=1.0.1.0
HWADDR=56:EF:25:79:B7:BF
DEVICE=bond50:0
IPV6INIT=no
## Optional, use for jumbo frames if needed
#MTU=9000
NM_CONTROLLED=no
NOZEROCONF=yes
ONBOOT=yes
BONDING_OPTS="miimon=100 mode=802.3ad lacp_rate=1"
|
Tras el reinicio del servicio de networking todo deberá funcionar correctamente.
En el caso de que se quiera utilizar un pool de IPs, por ejemplo 1.0.1.81 - 1.0.1.89, en lugar de una única dirección, se deberá seguir el mismo procedimiento para crear IP Alias pero en este caso en lugar de copiar el fichero del interfaz, se creará uno nuevo siguiendo la terminología ifcfg-xxxx-range0, no obstante también hay que configurar la regla IPTABLES para realizar el SNAT al pool de IPs:
iptables -t nat -A POSTROUTING -o bond50 -s 5.5.5.0/24 -j SNAT --to-source 1.0.1.81-1.0.1.89 ! -d 5.5.5.0/24
La creación de los IP Alias se realizaría del modo que se ha comentado, creando un nuevo fichero de interfaz:
vi /etc/sysconfig/network-scripts/ifcfg-bond50-range0
El contenido de este fichero, para ese pool, sería el siguiente:
En el caso de que se quiera utilizar un pool de IPs, por ejemplo 1.0.1.81 - 1.0.1.89, en lugar de una única dirección, se deberá seguir el mismo procedimiento para crear IP Alias pero en este caso en lugar de copiar el fichero del interfaz, se creará uno nuevo siguiendo la terminología ifcfg-xxxx-range0, no obstante también hay que configurar la regla IPTABLES para realizar el SNAT al pool de IPs:
iptables -t nat -A POSTROUTING -o bond50 -s 5.5.5.0/24 -j SNAT --to-source 1.0.1.81-1.0.1.89 ! -d 5.5.5.0/24
La creación de los IP Alias se realizaría del modo que se ha comentado, creando un nuevo fichero de interfaz:
vi /etc/sysconfig/network-scripts/ifcfg-bond50-range0
El contenido de este fichero, para ese pool, sería el siguiente:
IPADDR_START=1.0.1.81
IPADDR_END=1.0.1.89 CLONENUM_START=1 NETMASK=255.255.255.0 |
El parámetro CLONENUM_START es el número de Alias de IP por el que comenzará. En este caso es "1", por lo que la IP 1.0.1.81 será la interfaz bond50:1, la .82 la bond50:2, y así sucesivamente.
Tras el reinicio del servicio de red, se puede comprobar la configuración utilizando el comando ifconfig:
…
bond50:0 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.92 Bcast:1.0.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1 bond50:1 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.81 Bcast:1.0.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1 bond50:2 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.82 Bcast:1.0.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1 bond50:3 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.83 Bcast:1.0.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1 bond50:4 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.84 Bcast:1.0.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1 bond50:5 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.85 Bcast:1.0.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1 bond50:6 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.86 Bcast:1.0.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1 bond50:7 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.87 Bcast:1.0.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1 bond50:8 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.88 Bcast:1.0.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1 bond50:9 Link encap:Ethernet HWaddr 00:0C:29:E3:0F:DE inet addr:1.0.1.89 Bcast:1.0.1.255 Mask:255.255.255.0
UP BROADCAST
RUNNING MASTER MULTICAST MTU:1500 Metric:1
…
|
Ya se ha repasado como realizar SNAT utilizando la IP del bond externo, otra IP que no está asignada al bond y un SNAT especificando un rango de IPs. A continuación se explicará la configuración necesaria para la realización del NAT de origen utilizando dinámicamente IPs, sin necesidad de indicárselas específicamente en la configuración del NAT (lo que se llama MASQUERADING).
La utilización de MASQUEDADING, a parte de aportar menor control sobre las IPs utilizadas, debería restringirse únicamente para las interfaces a las cuales se les asigna dinámicamente la IP (Dialup connections), según se indica la ayuda de iptables, ya que el manejo de las sesiones en SNAT es mejor que en MASQUERADE (incluso ante breves cortes del interfaz, las sesiones pueden persistir).
No obstante, ya que con la utilización de libvirt es el tipo de NAT de origen que se implementa, en este ejemplo de configuración manual también se procederá a la utilización de MASQUERADING.
Para la su configuración se utilizará el siguiente comando:
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -j MASQUERADE ! -d 5.5.5.0/24
Para asemejar aún más la configuración realizada manualmente, a la que realiza libvirt, se seleccionarán los puertos TCP utilizados como origen tras el NAT de orgien, estos serán del 1024 al 65535. Esto se realiza para no ocupar puertos TCP "conocidos", que son los inferiores al 1024, y que pueden estar en uso por la la IP del bond.
Al seleccionar los puertos la regla se ha de dividir en dos: una regla TCP y otra UDP:
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -p tcp -j MASQUERADE --to-ports 1024-65535 ! -d 5.5.5.0/24
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -p udp -j MASQUERADE --to-ports 1024-65535 ! -d 5.5.5.0/24
Para completar a las dos anteriores reglas, se generará una adicional sin especificar los puertos, utilizando el comando mostrado anteriormente:
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -j MASQUERADE ! -d 5.5.5.0/24
Utilizando los tres últimos comandos, se despliega la configuración final utilizada en este ejemplo. Para verificar las reglas creadas dentro de la tabla iptables, se puede usar este comando:
Es importante recordar que para que las reglas sean conservadas tras los reinicios del Host, habrá que incluirlas en el fichero /etc/sysconfig/iptables. Para ello habrá que incluir una nueva sección en el fichero llamada "nat", como se puede ver en la siguiente captura:
La utilización de MASQUEDADING, a parte de aportar menor control sobre las IPs utilizadas, debería restringirse únicamente para las interfaces a las cuales se les asigna dinámicamente la IP (Dialup connections), según se indica la ayuda de iptables, ya que el manejo de las sesiones en SNAT es mejor que en MASQUERADE (incluso ante breves cortes del interfaz, las sesiones pueden persistir).
No obstante, ya que con la utilización de libvirt es el tipo de NAT de origen que se implementa, en este ejemplo de configuración manual también se procederá a la utilización de MASQUERADING.
Para la su configuración se utilizará el siguiente comando:
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -j MASQUERADE ! -d 5.5.5.0/24
Para asemejar aún más la configuración realizada manualmente, a la que realiza libvirt, se seleccionarán los puertos TCP utilizados como origen tras el NAT de orgien, estos serán del 1024 al 65535. Esto se realiza para no ocupar puertos TCP "conocidos", que son los inferiores al 1024, y que pueden estar en uso por la la IP del bond.
Al seleccionar los puertos la regla se ha de dividir en dos: una regla TCP y otra UDP:
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -p tcp -j MASQUERADE --to-ports 1024-65535 ! -d 5.5.5.0/24
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -p udp -j MASQUERADE --to-ports 1024-65535 ! -d 5.5.5.0/24
Para completar a las dos anteriores reglas, se generará una adicional sin especificar los puertos, utilizando el comando mostrado anteriormente:
iptables -t nat -A POSTROUTING -s 5.5.5.0/24 -o bond50 -j MASQUERADE ! -d 5.5.5.0/24
iptables --line-numbers -n -v -L -t nat
Esta sería la salida:
| [root@kvm1
~]# iptables --line-numbers -n -v -L -t nat Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 0 0 MASQUERADE tcp -- * bond50 5.5.5.0/24 !5.5.5.0/24 masq ports: 1024-65535 2 0 0 MASQUERADE udp -- * bond50 5.5.5.0/24 !5.5.5.0/24 masq ports: 1024-65535 3 0 0 MASQUERADE all -- * bond50 5.5.5.0/24 !5.5.5.0/24 |
Es importante recordar que para que las reglas sean conservadas tras los reinicios del Host, habrá que incluirlas en el fichero /etc/sysconfig/iptables. Para ello habrá que incluir una nueva sección en el fichero llamada "nat", como se puede ver en la siguiente captura:
# Firewall configuration written by system-config-firewall
# Manual customization of this file is not recommended.
*nat
:PREROUTING ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A POSTROUTING -s 5.5.5.0/24 -o bond50 -p tcp -j MASQUERADE --to-ports 1024-65535 ! -d 5.5.5.0/24
-A POSTROUTING -s 5.5.5.0/24 -o bond50 -p udp -j MASQUERADE --to-ports 1024-65535 ! -d 5.5.5.0/24
-A POSTROUTING -s 5.5.5.0/24 -o bond50 -j MASQUERADE ! -d 5.5.5.0/24
COMMIT
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -i bond50 -o br50 -d 5.5.5.0/24 -j ACCEPT
-A FORWARD -i br50 -o bond50 -s 5.5.5.0/24 -j ACCEPT
-A FORWARD -i br50 -o br50 -j ACCEPT
-A FORWARD -o br50 -j REJECT
-A FORWARD -i br50 -j REJECT
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
|
Si además del NAT de salida se necesitase realizar NAT de conexiones entrantes, redirigiéndolas a alguna máquina virtual, se hará uso de las reglas tipo PREROUTING. Este sería un ejemplo para redirigir el tráfico destinado a la IP externa del bond (1.0.1.95):
iptables -t nat -I PREROUTING -p tcp -d 1.0.1.95 --dport 80 -j DNAT --to-destination 5.5.5.8:80
Con el forwarding/NAT ya configurado, el siguiente paso sería la configuración de reglas de enrutamiento en el caso de ser necesarias.
El Host KVM debe disponer de la ruta por defecto como mínimo, y para comprobarlo se hará uso del comando:
netstat -r
De no estar presente la ruta por defecto (la que tiene como destino default), o si se necesitase incorporar rutas específicas para alcanzar alguna red, se podría agregar creando un fichero de rutas para la interfaz externa:
vi /etc/sysconfig/network-scripts/route-bond50
En este fichero se incorporarían las rutas. En el siguiente ejemplo se muestra la el contenido del fichero, con la ruta por defecto y otra para la red 88.88.88.0/24, la cual alcanza mediante el router con la IP 1.0.1.55:
0.0.0.0/0 via 1.0.1.1
88.88.88.0/24 via 1.0.1.55 |
Se debe reiniciar el servicio de red para que se active el anterior fichero:
La ruta por defecto también se pueden incluir en el fichero /etc/sysconfig/network con el parámetro GATEWAY.
service network restart
La ruta por defecto también se pueden incluir en el fichero /etc/sysconfig/network con el parámetro GATEWAY.
Hay que recordar que, aparte de las rutas que se han de incluir en el Host KVM, se deberá añadir la ruta por defecto a las máquinas virtuales, cuya IP será la del bridge a la que esté conectada.
Con todo lo anterior ya se dispondrá de la conectividad L2 y L3 configurada:
Figura 28 - Representación de la conectividad L2 y L3 del ejemplo de configuración manual
Por último, tras la incorporación de las rutas, si se cree necesario, se pueden activar servicios añadidos como DHCP, DNS, TFTP, NTP, QoS, etc. También es posible que estos servicios lo proporcionen directamente servidores externos al Host KVM.
En este ejemplo, se configurará el servicio DHCP y DNS para las redes virtuales creadas anteriormente. Para proporcionar estos servicios se pueden utiliza cualquier software servidor compatible con el Sistema Operativo del Host KVM. En este ejemplo de configuración manual se utilizará el Software dnsmasq ya que es el que utiliza libvirt para proporcionar esos mismos servicios.
El servidor dnsmasq proporciona un método sencillo de poner en marcha servidores DNS, DHCP y TFTP para redes de tamaño pequeño. En el caso del DNS, este reenviará las peticiones a las IPs de los servidores DNS que tengan configurado el host KVM, por ello como primer paso para proporcionar DNS a las máquinas virtuales, se deberán configurar los servidores DNS dentro de la propia máquina Host KVM, para que este pueda saber a quién reenviar la peticiones. Para ello se deben incluir los servidores en el fichero /etc/resolv.conf:
vi /etc/resolv.conf
search localdomain
nameserver 8.8.8.8 nameserver 4.2.2.2 |
En este caso se tienen configurados los servidores DNS 8.8.8.8 y 4.2.2.2.
Para que los cambios se hagan efectivos se necesitará reiniciar el servicio de red, del mismo modo que se ha hecho en anteriores ocasiones:
service network restart
La configuración de dnsmasq (si ya está instalado en el Host) se puede realizar mediante la modificación del fichero "/etc/dnsmasq.conf", pero ya que se podrán tener varios bridges para máquinas virtuales, es más sencillo ejecutar una nueva instancia de dnsmasq con los parámetros adecuados por cada virtual network que se quiera implementar. El comando para iniciar la instancia de dnsmasq, que proporcione forwarding DNS, y DHCP para el bridge 50 (rango 5.5.5.128 - 5.5.5.254) sería el siguiente:
dnsmasq --strict-order --conf-file= --except-interface lo --bind-interfaces --listen-address 5.5.5.1 --dhcp-range 5.5.5.128,5.5.5.254 --dhcp-leasefile=/var/lib/libvirt/dnsmasq/br50.leases --dhcp-lease-max=127 --dhcp-no-override --dhcp-hostsfile=/var/lib/libvirt/dnsmasq/br50.hostsfile --addn-hosts=/var/lib/libvirt/dnsmasq/br50.addnhosts
Para que los cambios se hagan efectivos se necesitará reiniciar el servicio de red, del mismo modo que se ha hecho en anteriores ocasiones:
service network restart
La configuración de dnsmasq (si ya está instalado en el Host) se puede realizar mediante la modificación del fichero "/etc/dnsmasq.conf", pero ya que se podrán tener varios bridges para máquinas virtuales, es más sencillo ejecutar una nueva instancia de dnsmasq con los parámetros adecuados por cada virtual network que se quiera implementar. El comando para iniciar la instancia de dnsmasq, que proporcione forwarding DNS, y DHCP para el bridge 50 (rango 5.5.5.128 - 5.5.5.254) sería el siguiente:
dnsmasq --strict-order --conf-file= --except-interface lo --bind-interfaces --listen-address 5.5.5.1 --dhcp-range 5.5.5.128,5.5.5.254 --dhcp-leasefile=/var/lib/libvirt/dnsmasq/br50.leases --dhcp-lease-max=127 --dhcp-no-override --dhcp-hostsfile=/var/lib/libvirt/dnsmasq/br50.hostsfile --addn-hosts=/var/lib/libvirt/dnsmasq/br50.addnhosts
En el comando se le especifica que dnsmasq "escuche" en la IP del bridge br50 (5.5.5.1), que será el default gateway de ese virtual network. También, además del rango DHCP, se indican otros parámetros, como que envíe las peticiones a los servidores DNS del fichero resolve.conf siguiendo el orden en el que aparecen en ese mismo fichero (strict-order) y que en ningún caso escuche en el interfaz local. También se especifica que no utilice ningún fichero de configuración adicional (conf-file).
Del mismo modo, se indican varios ficheros:
- El fichero donde se almacena la información sobre el lease DHCP para esa red virtual (br50.leases en este caso),
- Un fichero para almacenar la información de DHCP sobre las IPs vinculadas a cada MAC (br50.hostsfile)
- Un fichero en el que figuran los bindings entre hosts e IPs(br50.addnhosts), el cual será leido en lugar del fichero /etc/hosts del KVM
Todos estos ficheros están vacíos en esta configuración de ejemplo, pero es buena idea contar con ellos en el lanzamiento del comando por si en el futuro quieren ser utilizados.
Se puede confirmar que el comando se hizo efectivo comprobando que el Host KVM está escuchando el puerto DNS (53) en la dirección IP 5.5.5.1:
| [root@kvm1
~]# netstat -anp | grep 5.5.5.1 tcp 0 0 5.5.5.1:53 0.0.0.0:* LISTEN 10956/dnsmasq udp 0 0 5.5.5.1:53 0.0.0.0:* 10956/dnsmasq |
También se puede revisar el servicio DHCP:
vi /etc/rc.d/rc.local
| [root@kvm1 ~]# netstat -anp | grep :67 udp 0 0 0.0.0.0:67 0.0.0.0:* 2724/dnsmasq |
Como es de esperar, tras el reinicio del Host KVM se deberá volver a lanzar el comando, por lo que se necesita incluirlo en los scripts de inicio del Host. Para el caso del ejemplo que se está mostrando, en el cual se utiliza RHEL, para incluir los comandos al inicio se ha de incluir en el fichero /etc/rc.d/rc.local:
vi /etc/rc.d/rc.local
#!/bin/sh
# # This script will be executed *after* all the other init scripts. # You can put your own initialization stuff in here if you don't # want to do the full Sys V style init stuff. touch /var/lock/subsys/local # DNSMASQ dnsmasq --strict-order --conf-file= --except-interface lo --bind-interfaces --listen-address 5.5.5.1 --dhcp-range 5.5.5.128,5.5.5.254 --dhcp-leasefile=/var/lib/libvirt/dnsmasq/br50.leases --dhcp-lease-max=127 --dhcp-no-override --dhcp-hostsfile=/var/lib/libvirt/dnsmasq/br50.hostsfile --addn-hosts=/var/lib/libvirt/dnsmasq/br50.addnhosts |
Es muy importante recordar que al estar activo iptables, si se desea implementar cualquier servicio en alguna interfaz del Host KVM, se deberá permitir explícitamente en la configuración iptables, ya que de no ser así, el tráfico será descartado.
Como se debe proveer servicio DNS (puerto 53) y DHCP (puerto ) en la interfaz br50 (IP 5.5.5.1), se deberán incluir estas reglas a la configuración iptables:
Para introducir estas reglas se pueden utilizar los comandos iptables, pero debido a que también hay que hacer una reorganización de las políticas actuales, ya que existe una regla que deniega todas las entradas a las interfaces, y al crear las nuevas reglas se situarían debajo de estas, lo mejor será editar el fichero /etc/sysconfig/iptables, de modo quedaría de la siguiente manera:
vi /etc/sysconfig/iptables
Tras modificar el fichero se puede reinicar el servicio iptables para que se hagan efectivas las nuevas reglas. En Sistemas operativos tipo RHEL:
service iptables restart
Como se debe proveer servicio DNS (puerto 53) y DHCP (puerto ) en la interfaz br50 (IP 5.5.5.1), se deberán incluir estas reglas a la configuración iptables:
- Regla para permitir el acceso a los puertos UDP y TCP 53 para el servicio DNS en el interfaz br50
- Regla que permita el acceso a los puertos UDP y TCP 67, para el DHCP en el interfaz br50
Para introducir estas reglas se pueden utilizar los comandos iptables, pero debido a que también hay que hacer una reorganización de las políticas actuales, ya que existe una regla que deniega todas las entradas a las interfaces, y al crear las nuevas reglas se situarían debajo de estas, lo mejor será editar el fichero /etc/sysconfig/iptables, de modo quedaría de la siguiente manera:
vi /etc/sysconfig/iptables
# Firewall configuration written by system-config-firewall
# Manual customization of this file is not recommended.
*nat
:PREROUTING ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A POSTROUTING -s 5.5.5.0/24 -o bond50 -p tcp -j MASQUERADE --to-ports 1024-65535 ! -d 5.5.5.0/24
-A POSTROUTING -s 5.5.5.0/24 -o bond50 -p udp -j MASQUERADE --to-ports 1024-65535 ! -d 5.5.5.0/24
-A POSTROUTING -s 5.5.5.0/24 -o bond50 -j MASQUERADE ! -d 5.5.5.0/24
COMMIT
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -i br50 -p tcp --dport 53 -j ACCEPT
-A INPUT -i br50 -p udp --dport 53 -j ACCEPT
-A INPUT -i br50 -p tcp --dport 67 -j ACCEPT
-A INPUT -i br50 -p udp --dport 67 -j ACCEPT
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -i bond50 -o br50 -d 5.5.5.0/24 -j ACCEPT
-A FORWARD -i br50 -o bond50 -s 5.5.5.0/24 -j ACCEPT
-A FORWARD -i br50 -o br50 -j ACCEPT
-A FORWARD -o br50 -j REJECT
-A FORWARD -i br50 -j REJECT
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
|
Como se aprecia, las nuevas reglas INPUT se han situado por delante de las que ya se encontraban existentes.
Tras modificar el fichero se puede reinicar el servicio iptables para que se hagan efectivas las nuevas reglas. En Sistemas operativos tipo RHEL:
service iptables restart
Con esto, la tabla de filtering iptables sería la siguiente:
Por su lado, la tabla de NAT de iptables no se ha cambiado.
| [root@kvm1
~]# iptables --line-numbers -v -L Chain INPUT (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 0 0 ACCEPT tcp -- br50 any anywhere anywhere tcp dpt:domain 2 0 0 ACCEPT udp -- br50 any anywhere anywhere udp dpt:domain 3 0 0 ACCEPT tcp -- br50 any anywhere anywhere tcp dpt:bootps 4 0 0 ACCEPT udp -- br50 any anywhere anywhere tcp dpt:bootps 5 23 2008 ACCEPT all -- any any anywhere anywhere state RELATED,ESTABLISHED 6 0 0 ACCEPT icmp -- any any anywhere anywhere 7 0 0 ACCEPT all -- lo any anywhere anywhere 8 0 0 ACCEPT tcp -- any any anywhere anywhere state NEW tcp dpt:ssh 9 0 0 REJECT all -- any any anywhere anywhere reject-with icmp-host-prohibited Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) num pkts bytes target prot opt in out source destination 1 0 0 ACCEPT all -- bond50 br50 anywhere 5.5.5.0/24 2 0 0 ACCEPT all -- br50 bond50 5.5.5.0/24 anywhere 3 0 0 ACCEPT all -- br50 br50 anywhere anywhere 4 0 0 REJECT all -- any br50 anywhere anywhere reject-with icmp-port-unreachable 5 0 0 REJECT all -- br50 any anywhere anywhere reject-with icmp-port-unreachable 6 0 0 REJECT all -- any any anywhere anywhere reject-with icmp-host-prohibited Chain OUTPUT (policy ACCEPT 19 packets, 2584 bytes) num pkts bytes target prot opt in out source destination |
Esta sería la representación gráfica de la configuración llegado este punto:
Figura 29 - Representación de la conectividad y servicios añadidos en ejemplo de configuración manual
En este momento ya se podrá crear una máquina virtual y vincularla al bridge br50:
virt-install --name=VM_L3_test --arch=x86_64 --vcpus=1 --ram=512 --os-type=linux --hvm --connect=qemu:///system --network bridge:br50 --vnc --noautoconsole --nodisk --boot cdrom
Una vez creada y ejecutada la máquina virtual, se puede comprobar cómo el servicio DHCP ha funcionado correctamente, consultando el fichero de leases para el bridge y viendo cómo se ha asignado correctamente la IP:
| [root@kvm1
~]# cat /var/lib/libvirt/dnsmasq/br50.leases 1403532911 52:54:00:a9:d1:4e 5.5.5.164 * 01:52:54:00:a9:d1:4e |
Con este último paso se completaría el esquema buscado:
Figura 30 - Representación de la conectividad final en ejemplo de configuración manual
Configuración con libvirt (CLI)
Se llevará a cabo una configuración similar a la del ejemplo manual, pero creada a partir de ficheros XML importados mediante el comando virsh, tal y como se vio en los ejemplos del bridged mode.
Los pasos a seguir serán los mismos que en el ejemplo de configuración manual:
- Creación de conexión L2 externa (bonding) del bridge interno para la conexión de VMs
- Activación de IP forwarding en el Host
- Configuración de políticas L3 (y NAT si se necesitase)
- Configuración de rutas
- Configuración de servicios añadidos (por ejemplo DHCP y DNS).
De estos pasos hay dos que se deberán seguir haciendo manualmente:
- Activación de IP forwarding en el Host
- Configuración de rutas
Y el resto se podrán hacer mediante libvirt:
- Creación de conexión L2 externa (bonding) del bridge interno para la conexión de VMs
- Configuración de políticas L3 (y NAT si se necesitase)
- Configuración de servicios añadidos (por ejemplo DHCP y DNS).
Por ello primero se configurarán los parámetros manuales.La habilitación del forwarding se debe hacer siguiendo el mismo procedimiento manual que en el anterior ejemplo. Como ya se hizo en aquel momento, se puede comprobar como el parámetro sigue activo (igual a "1"):
[root@kvm1 ~]# cat /etc/sysctl.conf | grep net.ipv4.ip_forward
net.ipv4.ip_forward = 1 |
Por su lado, la incorporación de las rutas también se realizará de un modo similar:
vi /etc/sysconfig/network-scripts/route-bond800
En este fichero se podrían incluir la ruta por defecto y, por ejemplo, otra adicional:
0.0.0.0/0 via 1.0.1.1
88.88.88.0/24 via 1.0.1.55 |
Antes de proceder con la configuración del resto de parámetros con libvirt, se ha de señalar que en el ejemplo de configuración del bridge mode se trabajó con el comando "virsh iface-*", el cual permitía gestionar los bridges y los bondings, mientras que para el routed mode, donde en realidad se está creando una red virtual, se utilizarán los comandos "virsh net-*".
Se puede ver como "virsh iface-list" muestra los bonding y bridges creados en los ejemplos anteriores:
[root@kvm1 ~]# virsh iface-list --all
Name State MAC Address
--------------------------------------------
bond100 active 00:00:00:00:00:00
bond2 active 00:0c:29:e3:0f:2e
bond50 active 00:0c:29:e3:0f:de
bond50.66 active 00:0c:29:e3:0f:de
bond50.67 active 00:0c:29:e3:0f:de
br125 active 00:0c:29:e3:0f:f2
br126 active 00:0c:29:e3:0f:f2
br15 active 00:0c:29:e3:0f:2e
br16 active 00:0c:29:e3:0f:2e
br50 active fe:54:00:a9:d1:4e
br555 active 3e:fe:b0:fb:44:98
br556 active b6:51:35:02:bf:53
eth0 active 00:0c:29:e3:0f:d4
eth3 active 00:0c:29:e3:0f:06
lo active 00:00:00:00:00:00
|
Pero para revisar el conjunto del bridge interno al que se conectarán las máquinas virtuales, más las políticas de iptables de forwarding y NAT, más los servicios añadidos DHCP y DNS, se haría mediante el comando "virsh net-*".
Si se ejecuta virsh net-list se puede ver que aparece vacío porque todavía no se ha creado nada, no obstante debería existir un virtual network llamado "default", que por defecto ya está creado, pero el cual fue borrado durante el transcurso del ejemplo anterior (configuración manual del routed mode).
Se crea el fichero XML para la definición del bonding (sin bridge asociado). También se debe recordar que es necesario añadir la configuración de las IPs:
Y más tarde se activa:
Ya se dispondría de este esquema:

Figura 31 - Representación del bonding en ejemplo de configuración con libvirt (CLI)
Con el bonding ya configurado, se puede crear la virtual network. Como ya se ha comentado, hay tres tipos de "redes virtuales":
Como la red aislada no tiene complicación, y la red enrutada está contenida en al enrutada con NAT, nuevamente en este ejemplo de configuración con libvirt se desplegará la red virtual con NAT, del mismo modo que se hizo en el ejemplo de configuración manual.
Para crear el bridge interno, más las políticas de iptables (incluido el NAT) más DNS+DHCP, se podría crear un fichero como el siguiente:
vi make_virtualnet1.xml
Tras esto ya aparecerá en el listado de networks virtuales (recordar poner el modificador --all porque al sino no aparecería al estar inactiva todavía):
Pero para que la red sea marcada para su autoinicio, se debe incluir el comando:
virsh net-autostart virtualnet1
Tras su ejecución se puede ver cómo aparece Autostart=yes:
Tras esta importación, se puede comprobar cómo se ha formado el nuevo bridge al que se conectarán las máquinas virtuales, llamado virtualbr0:
Como primer paso se creará el bond500 (en este ejemplo también se utilizará únicamente el bond500, omitiendo las VLANs para no complicar demasiado la configuración).
vi make_bond800.xml
<interface type='bond' name='bond800'>
<protocol family='ipv4'><ip address='1.0.1.195' prefix='24'/> </protocol>
<start mode="onboot"/>
<bond mode="802.3ad">
<interface type='ethernet' name='eth8'>
<mac address='00:0C:29:E3:0F:DE'/>
</interface>
<interface type='ethernet' name='eth9'>
<mac address='00:0C:29:E3:0F:DE'/>
</interface>
</bond>
</interface>
|
Luego se definen las interfaces con virsh utilizando esos ficheros:
[root@kvm1 ~]# virsh iface-define make_bond800.xml
Interface bond800 defined from /root/
|
Y más tarde se activa:
[root@kvm1 ~]# virsh iface-start bond800
Interface bond800 started |
Hay que recordar cambiar los parámetros de bonding para que funcione correctamente el LACP. Se comprueba que cuando se ha creado el fichero aparecen las BONDING_OPTS que hay que cambiar:
Se debe sustituir el parámetro para que el fichero quede de la siguiente manera:
[root@kvm1 ~]# cat /etc/sysconfig/network-scripts/ifcfg-bond800
DEVICE=bond800 ONBOOT=yes BOOTPROTO=none IPADDR=1.0.1.195 NETMASK=255.255.255.0 BONDING_OPTS="'mode=802.3ad'" |
Se debe sustituir el parámetro para que el fichero quede de la siguiente manera:
DEVICE=bond800
ONBOOT=yes
BOOTPROTO=none
IPADDR=1.0.1.195
NETMASK=255.255.255.0
BONDING_OPTS="miimon=100 mode=802.3ad lacp_rate=1"
|
Figura 31 - Representación del bonding en ejemplo de configuración con libvirt (CLI)
Con el bonding ya configurado, se puede crear la virtual network. Como ya se ha comentado, hay tres tipos de "redes virtuales":
- Red Aislada: En este tipo de red tan solo se crearía el bridge al que se conectan las máquinas y tal vez se le añadirían servicios como DHCP. No hay enrutamiento en realidad
- Red Enrutada: Se crea el bridge interno y se configura el enrutamiento hacia un interfaz/bonding que conecte con las redes externas
- Red Enrutada con NAT: Lo mismo que la red enrutada pero a la vez se configura el NAT de salida.
Como la red aislada no tiene complicación, y la red enrutada está contenida en al enrutada con NAT, nuevamente en este ejemplo de configuración con libvirt se desplegará la red virtual con NAT, del mismo modo que se hizo en el ejemplo de configuración manual.
Para crear el bridge interno, más las políticas de iptables (incluido el NAT) más DNS+DHCP, se podría crear un fichero como el siguiente:
vi make_virtualnet1.xml
<network>
<name>virtualnet1</name> <forward dev='bond800' mode='nat'> <interface dev='bond800'/> </forward> <bridge name='virtualbr0' stp='off' /> <mac address='D0:17:B4:3F:8F:6F'/> <ip address='99.99.99.1' netmask='255.255.255.0'> <dhcp> <range start='99.99.99.128' end='99.99.99.254' /> </dhcp> </ip>
</network>
|
Como se puede ver, en el fichero se indican todos los aspectos ya vistos:
- Directiva <forward>, donde se indica el interfaz externo (bond800) al que se le permitirá la realización de forwarding, que se realizará NAT (si se quisiese una red enrutada sin nat, en lugar de indicar mode='nat' se deberá poner mode='route')
- Directiva <bridge>, donde se especifica el nombre del bridge interno al que se conectan las máquinas virtuales
- La IP del bridge
- Los rangos de direcciones IPs que asignará el DHCP
Ese fichero se utilizará para definir la nueva red virtual:
[root@kvm1 ~]# virsh net-define make_virtualnet1.xml
Network virtualnet1 defined from make_virtualnet1.xml
|
Tras esto ya aparecerá en el listado de networks virtuales (recordar poner el modificador --all porque al sino no aparecería al estar inactiva todavía):
[root@kvm1 ~]# virsh net-list --all
Name State Autostart Persistent
--------------------------------------------------
virtualnet1 inactive no yes
|
Pero para que la red sea marcada para su autoinicio, se debe incluir el comando:
virsh net-autostart virtualnet1
Tras su ejecución se puede ver cómo aparece Autostart=yes:
[root@kvm1 ~]# virsh net-list --all
Name State Autostart Persistent
--------------------------------------------------
virtualnet1 inactive yes yes
|
Tras esta importación, se puede comprobar cómo se ha formado el nuevo bridge al que se conectarán las máquinas virtuales, llamado virtualbr0:
[root@kvm1 ~]# brctl show
bridge name bridge
id STP enabled interfaces
br125 8000.000000000000 no
br126 8000.000000000000 no
br15 8000.000c29e30f2e no bond2.15
br16 8000.000c29e30f2e no bond2.16
br50 8000.000000000000 no
br555
8000.000000000000 no
br556
8000.000000000000 no
virtualbr0
8000.d017b43f8f6f no virtualbr0-nic
|
Este bridge no aparecerá en los ficheros situados en /etc/sysconfig/network-scripts/ ya que libvirt los crea dinámicamente y no de forma estática permanente, que es lo que harían los ficheros.
Se puede apreciar que, además del bridge, se ha creado una NIC virtual llamada virtualbr0-nic. Esta es creada para proporcionar al bridge una MAC estable (la MAC que se le asigna en el XML). Durante la configuración manual, para fijar la MAC y evitar que esta no variase según se creaban y destruían máquinas virtuales, se especificó en el propio fichero del bridge con el modificador MACADDR. Ahora se puede ver cómo libvirt utiliza el otro método que se comentó, el de crear una NIC virtual que solo es utilizada para "proporcionar" esa MAC estable al bridge.
A parte de la creación del bridge, también se puede comprobar que se han incluido las reglas de iptables:
[root@kvm1
~]# iptables --line-numbers -n -v -L
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in
out source
destination
1 0 0 ACCEPT
udp -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
udp dpt:53
2 0 0 ACCEPT
tcp -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
tcp dpt:53
3 0 0 ACCEPT
udp -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
udp dpt:67
4 0 0 ACCEPT
tcp -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
tcp dpt:67
5 0 0 ACCEPT
tcp -- br50 * 0.0.0.0/0
0.0.0.0/0
tcp dpt:53
6 0 0 ACCEPT
udp -- br50 * 0.0.0.0/0
0.0.0.0/0
udp dpt:53
7 0 0 ACCEPT
tcp -- br50 * 0.0.0.0/0
0.0.0.0/0
tcp dpt:67
8 0 0 ACCEPT
udp -- br50 * 0.0.0.0/0
0.0.0.0/0
udp dpt:67
9 30140 2556K ACCEPT all --
* * 0.0.0.0/0
0.0.0.0/0 state
RELATED,ESTABLISHED
10 2 144 ACCEPT icmp
-- * * 0.0.0.0/0
0.0.0.0/0
11 0 0 ACCEPT
all -- lo * 0.0.0.0/0
0.0.0.0/0
12 2 104 ACCEPT tcp
-- * * 0.0.0.0/0
0.0.0.0/0
state NEW tcp dpt:22
13 547 42666 REJECT all --
* * 0.0.0.0/0
0.0.0.0/0
reject-with icmp-host-prohibited
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in
out source
destination
1 0 0 ACCEPT
all -- bond800 virtualbr0 0.0.0.0/0
99.99.99.0/24 state
RELATED,ESTABLISHED
2 0 0 ACCEPT
all -- virtualbr0 bond800 99.99.99.0/24
0.0.0.0/0
3 0 0 ACCEPT
all -- virtualbr0 virtualbr0 0.0.0.0/0
0.0.0.0/0
4 0 0 REJECT
all -- * virtualbr0 0.0.0.0/0
0.0.0.0/0
reject-with icmp-port-unreachable
5 0 0 REJECT
all -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
reject-with icmp-port-unreachable
6 0 0 ACCEPT
all -- bond50 br50 0.0.0.0/0
5.5.5.0/24
7 0 0 ACCEPT
all -- br50 bond50 5.5.5.0/24
0.0.0.0/0
8 0 0 ACCEPT
all -- br50 br50 0.0.0.0/0
0.0.0.0/0
9 0 0 REJECT
all -- * br50 0.0.0.0/0
0.0.0.0/0
reject-with icmp-port-unreachable
10 0 0 REJECT
all -- br50 * 0.0.0.0/0
0.0.0.0/0
reject-with icmp-port-unreachable
11 0 0 REJECT
all -- * * 0.0.0.0/0
0.0.0.0/0
reject-with icmp-host-prohibited
|
En las reglas se pueden apreciar:
- Las nuevas entradas para permitir las conexiones a DNS y DHCP, ya colocadas en el orden correcto:
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in
out source
destination
1 0 0 ACCEPT
udp -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
udp dpt:53
2 0 0 ACCEPT
tcp -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
tcp dpt:53
3 0 0 ACCEPT
udp -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
udp dpt:67
4 0 0 ACCEPT
tcp -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
tcp dpt:67
|
- Las entradas para permitir el forwarding entre la red virtual contenida en el nuevo bridge virtualbr0 y el bonding bond800, también en el lugar que les corresponde:
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in
out source
destination
1 0 0 ACCEPT
all -- bond800 virtualbr0 0.0.0.0/0
99.99.99.0/24 state
RELATED,ESTABLISHED
2 0 0 ACCEPT
all -- virtualbr0 bond800 99.99.99.0/24
0.0.0.0/0
3 0 0 ACCEPT
all -- virtualbr0 virtualbr0 0.0.0.0/0
0.0.0.0/0
4 0 0 REJECT
all -- * virtualbr0 0.0.0.0/0
0.0.0.0/0
reject-with icmp-port-unreachable
5 0 0 REJECT
all -- virtualbr0 * 0.0.0.0/0
0.0.0.0/0
reject-with icmp-port-unreachable
|
Nuevamente, si se desease permitir el tráfico entre redes virtuales, habría que crear manualmente las reglas de forwarding, ya que las nuevas reglas solo especifican como origen y destino el bond800 y el bridge virtualbr0.
También se pueden consultar las reglas de NAT:
[root@kvm1 ~]# iptables
--line-numbers -n -v -L -t nat
Chain PREROUTING (policy ACCEPT 173 packets, 13364 bytes)
num pkts bytes
target prot opt in out
source destination
Chain POSTROUTING (policy ACCEPT 1 packets, 328 bytes)
num pkts bytes
target prot opt in out
source destination
1 0 0 MASQUERADE tcp
-- * bond800
99.99.99.0/24
!99.99.99.0/24 masq ports:
1024-65535
2 0 0 MASQUERADE udp
-- * bond800
99.99.99.0/24
!99.99.99.0/24 masq ports:
1024-65535
3 0 0 MASQUERADE all
-- * bond800
99.99.99.0/24
!99.99.99.0/24
4 0 0 MASQUERADE tcp
-- * bond50
5.5.5.0/24
!5.5.5.0/24 masq ports:
1024-65535
5 0 0 MASQUERADE udp
-- * bond50
5.5.5.0/24
!5.5.5.0/24 masq ports:
1024-65535
6 0 0 MASQUERADE all
-- * bond50
5.5.5.0/24 !5.5.5.0/24
Chain OUTPUT (policy ACCEPT 1 packets, 328 bytes)
num pkts bytes
target prot opt in out
source destination
|
Como se puede ver, libvirt utiliza el modo MASQUERADE, creando las mismas tres reglas que se repasaron en el ejemplo de configuración manual.
Al ser MASQUERADE utilizará las IPs asignadas al bonding, en el caso del ejemplo la IP 1.0.1.195.
Por último, se puede comprobar que el servicio dnsmasq también se encuentra activo en el nuevo bridge (IP 99.99.99.1):
[root@kvm1 ~]# netstat -anp | grep :53
tcp 0
0 99.99.99.1:53 0.0.0.0:* LISTEN 50264/dnsmasq
tcp 0
0 5.5.5.1:53 0.0.0.0:* LISTEN 2447/dnsmasq
udp 0 0 99.99.99.1:53 0.0.0.0:* 50264/dnsmasq
udp 0 0 5.5.5.1:53 0.0.0.0:* 2447/dnsmasq
|
Es decir, ya se dispondría de este esquema:
Figura 32 - Representación final en ejemplo de configuración con libvirt (CLI)
Se podría entonces crear una máquina virtual de pruebas:
virt-install --name=VM_L3_testlibvirt --arch=x86_64 --vcpus=1 --ram=512 --os-type=linux --hvm --connect=qemu:///system --network bridge:virtualbr0 --vnc --noautoconsole --nodisk --boot cdrom
y comprobar que el servicio DHCP está funcionando (cuidado porque el nombre del fichero que crea automaticamente no es el del bridge, sino el del network, es decir "virtualnet1"):
| [root@kvm1 ~]# cat /var/lib/libvirt/dnsmasq/virtualnet1.leases 1403713314 52:54:00:9f:78:34 99.99.99.178 * 01:52:54:00:9f:78:34 |
Mediante libvirt se pueden crear redes virtuales de muchas maneras, tan solo basta con ver las posibilidades de firewall y los labels de XML que permite para hacerse una idea.
Configuración con libvirt (GUI)
Como ejemplo final se muestra la creación del virtual network mediante el GUI.
En este ejemplo no se incluyen las tareas manuales que ya se han mostrado en el ejemplo de libvirt (CLI), ya que los pasos serían los mismos. Aquí se va a mostrar como crear un virtual network con las mismas características que el anterior virtualnet1, pero claro está, con diferente nombre y direccionamiento IP.
Tras haber realizado los pasos manuales (creación del bond800 y de las rutas), y haber lanzado virt-manager (recordar tener habilitado el X11 forwarding y un servidor X11 ejecutandose en el cliente, tal y como se explicó en el ejemplo del bridged mode) se accederá a Edit > Connections Details:
Figura 33 - Acceso a la configuración de conectividad de VMs en virt-manager
En esta pantalla se puede ver la red virtual que antes se ha creado por el método CLI:
Figura 34 - Configuración de redes virtuales en virt-manager
Seleccionado abajo a la izquierda "Add Network" aparecerá un Wizard para la configuración de una nueva virtual network:
Figura 35 - Inicio de la creación de una red virtual en virt-manager
Se le asignará un nombre:
Figura 36 - Asignación del nombre de la red virtual en virt-manager
Un rango de direccionamiento:
Figura 37 - Asignación de direccionamiento de la red virtual en virt-manager
También se especificará si se desea activar el DHCP y los parámetros de este:
Figura 38 - Activación y configuración del servicio DHCP en virt-manager
Una vez completado el paso del DHCP, se deberá seleccionar el tipo de red virtual. Se puede elegir aislado ("isolated") o forwarding, para lo cual hay que elegir la interfaz externa a la que se enrutará el tráfico (bond800 en este ejemplo):
Figura 39 - Selección de la interfaz externa para el enrutamiento de la red virtual en virt-manager
Ya que se ha elegido el tipo forwarding, se debe hacer también la selección de si su comportamiento implicará NAT o solo será routing:
Figura 40 - Selección del tipo de red virtual en virt-manager
Una vez finalizado, y tras pulsar "Finish", en la pantalla general se podrán revisar los parámetros de la nueva red virtual. También se podrá consultar el nombre del nuevo bridge interno que se ha creado para conectar las máquinas virtuales, virbr0 en este caso:
Figura 41 - Revisión de la configuración de una red virtual en virt-manager
Con esto, ya se dispondrá de la red virtual, por lo que se podrá vincular a las máquinas virtuales. Si se crea una máquina virtual de pruebas nueva (siguiendo los mismos pasos que los mostrados en el ejemplo del bridge mode), cuando se procede a la selección de la conexión de la vNIC, ya aparecerán las redes virtuales, tanto la creada por CLI, como por GUI. Para utilizar la red creada manualmente, habría que seleccionar el bridge que se creo a tal efecto (br50):
Figura 42 - Selección de la red virtual para su uso en la vNIC de una VM en virt-manager
Para poder comprobar el funcionamiento del DHCP, o el resto de elementos, habrá que utilizar el CLI tal y como se ha visto en los ejemplos anteriores.
Impresionante. Un trabajo excelente.
ResponderEliminarHe configurado un cloud con VM's KVM y redes enrutadas, con salida a internet a través de un firewall Untangle instalado en otra KVM.
Todas las VM's tienen salida a internet, el servidor web, el servidor Bind9 DNS y el firewall untangle... cuando hago nslookup www.google.es me responden ok.
En el servidor web tengo instalado un agente noip2 que actualiza correctamente la IP dinánica..... y sin embargo no logro ver desde internet mi página web.
¿Crees que tiene que ver con las reglas iptables FORWARD o ya que responden a nslookup es más bien tema del firewall Untangle?
He llegado a tu blog después de mucho navegar y creo que podrías orientarme un poco.
Saludos.
Si no es mucha molestia, claro.
ResponderEliminarFelicidades por tener un blog tan fantástico. Su forma de presentar el tema y su control sobre su caso demuestran sus habilidades y profesionalismo. Aquí, para su publicación de blog adicional, hay un enlace web que debo sugerir relacionado con la dirección MAC por DNSCHECHER.ORG. Aquí están los enlaces
ResponderEliminarPara el generador de direcciones MAC generador de direcciones MAC .
Para búsqueda de direcciones MAC
Búsqueda de dirección MAC .
Consulte ese sitio web para obtener más herramientas relacionadas con DNS, IP y redes.